


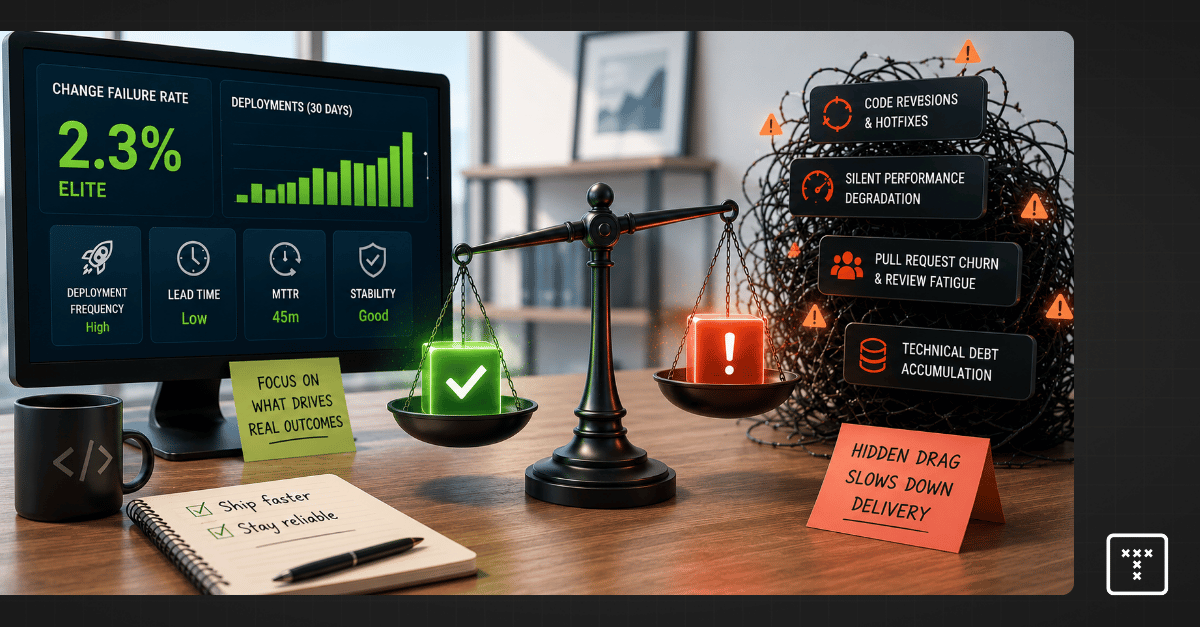
Change failure rate (CFR) measures the percentage of code deployments that result in a failure in production. The goal is to track how often your team pushes code that requires immediate remediation.
This metric serves as a critical counterbalance to deployment frequency. Optimizing strictly for speed often damages quality, so tracking failures ensures your team maintains system stability while shipping features faster. Engineering leaders use this DORA change failure rate signal to balance the inevitable tradeoff between quality versus speed.
Calculating this metric requires standardizing what counts as a deployment and what counts as a failure. You must define these terms consistently across your incident response tools and code repositories.
To calculate change failure rate, use this formula:
(Number of Failed Changes / Total Number of Changes) × 100
Industry benchmarks categorize engineering teams into performance tiers based on their ability to ship code reliably. According to the 2023 Accelerate State of DevOps Report by Google Cloud, you can measure change failure rate against these established standards to gauge your baseline delivery health.
Most engineering leaders limit the definition of failure strictly to hotfixes and rollbacks. This narrow scope misses the broader picture of system degradation.
If a deployment introduces massive technical debt or causes degraded service that doesn't trigger a critical alert, your dashboard will still show a success. This forces leaders to rely on intuition because incomplete data undermines the credibility of engineering reporting. Redefining failure for the modern era means looking at the entire workflow rather than just the final production state to capture the true cost of service patches.
Modern software delivery systems experience friction long before a catastrophic outage occurs. You must expand your definition of failure to capture the hidden costs of code delivery.
A dashboard can easily show an Elite status while your team is actually dealing with high pull request churn. This happens when teams game the metric or pollute the data with inconsistent definitions.
One common mistake is including fix-only deployments in the denominator of your calculation. If you push five hotfixes to resolve a single incident, counting those fixes as new deployments artificially lowers your failure rate. Another pitfall involves poor incident attribution, where third-party cloud outages are counted against internal team performance. These practices create a false sense of stability that operational intelligence must correct to restore trust in your reporting.
Executives must ensure their teams map incidents accurately across the software delivery lifecycle. Messy data makes it impossible to identify root causes and delays critical decision-making.
The rapid adoption of AI coding tools fundamentally changes how we measure delivery risk. These tools drastically increase developer output, so teams write and submit code faster than ever before. Yet this sheer volume of artificial intelligence-generated code contributions introduces unseen complexity into your repositories.
Downstream reviewers simply can't keep up with the flood of new pull requests. This imbalance creates severe review fatigue, where engineers lose the capacity to deeply inspect code for architectural flaws or long-term maintainability issues. The code compiles and passes basic tests, but the underlying structural health of the system degrades quietly.
Unmanaged complexity builds up in your repositories and creates massive workflow friction during the review stage. When a dense, highly complex pull request sits in review for days, engineers eventually rubber-stamp the approval just to clear their queues.
That code merges, sits in the pipeline, and fails days later in production. You then spend valuable engineering cycles on bug prioritization instead of shipping new features. The failure looks like a sudden event on your dashboard, but the root cause was the hidden complexity that bottlenecked your workflow days earlier.
Measuring a failure after it hits production is fundamentally a lagging indicator. Industry frameworks provide useful signals about your software delivery performance, but they don't provide an understanding of why that performance is changing. You need to know where risk enters your system before the code ships to production.
TargetBoard is an agentic operational intelligence platform that helps leadership teams understand how execution is performing, why it's changing, and how to respond. It connects data across company systems, interprets performance through operational intelligence, and uses domain-expert artificial intelligence agents to guide execution decisions.
By surfacing hidden risks like review fatigue, code anomalies, and workflow bottlenecks during the actual code review process, TargetBoard allows you to neutralize the root causes of failure before they merge. This shifts your posture from reactive reporting to proactive delivery confidence, ultimately driving true engineering efficiency.
You can actively prevent production failures by changing how your team handles code before it reaches the main branch. Aligned with the foundational Continuous Delivery principles established by industry experts like Jez Humble and Martin Fowler, shifting quality checks left is critical.
Pushing for speed without guardrails creates severe systemic tradeoffs. You must balance how fast you ship with how well your system actually runs.
Requires connecting cross-system data to accurately predict where failures will occur.
Redefining failure requires you to look beyond standard production deployments and measure the friction happening inside your daily workflows.
Your dashboard is only as valuable as the decisions it enables. Passive metrics show you what broke, so you must adopt active operational intelligence to see why it broke. Understanding these patterns gives you a clear framework to improve engineering efficiency and ensure long-term delivery predictability. Moving away from lagging scorecards allows you to scale your software delivery performance safely and build trust with your board.

What is velocity vs capacity in Agile? Understanding velocity vs. capacity comes down to separating what a team did in the past from what they can actually do right now. VPs of Engineering often treat velocity versus capacity as interchangeable data points during sprint planning. But they measure entirely different dimensions of engineering operations.
Velocity looks backward at what a team achieved, so it provides a baseline for expectations. Capacity looks forward at who is actually in the room, which grounds those expectations in reality. You can't build a reliable forecast using only one side of this equation.
Velocity is a lagging indicator that measures historical performance. It calculates the average number of completed story points a team delivered over recent sprints. This metric gives you a baseline of past performance under previous conditions. But it doesn't account for new complexities or current workflow friction.
Capacity is a leading indicator that defines future availability. It measures the actual time your team has to work on new commitments based on real-time constraints. This includes tracking team availability after accounting for meetings, operations overhead, and focus hours. Capacity tells you exactly who is in the room and ready to build.
You can't plan a sprint using only one side of the equation. If you only measure velocity, you will overcommit during weeks with high time off and PTO. If you only determine capacity, you lack a benchmark for how much work fits into those available hours. You must combine both to plan sprint cycles effectively.
Follow this sequence to align team commitments with actual execution reality.
Smart resource allocation requires you to commit to less work than your maximum mathematical capacity. This buffer creates a sustainable pace that absorbs complex pull request reviews and inevitable context switching. Operating at 100 percent capacity guarantees that any minor workflow friction will immediately derail your commitments.
Executives often conflate these distinct metrics when evaluating team performance. Understanding the difference between velocity, capacity, and load is critical for diagnosing why a team is burning out.
When team load consistently exceeds actual capacity, delivery predictability collapses. Teams will start cutting corners on code quality or accumulating technical debt just to maintain the illusion of stable velocity.
You have likely sat in a board meeting where engineering leadership reports a perfectly stable velocity, yet the actual product roadmap is slipping by weeks. This scenario sits at the center of the velocity vs capacity debate. The disconnect happens because velocity measures raw output, not true productivity.
A team can easily burn down 40 points of minor bug fixes while the core architectural work stalls completely. When executives treat velocity as a prescriptive performance target rather than a descriptive planning tool, they incentivize measurement theater. Engineers start optimizing for story points to keep the charts looking green, sacrificing sustainable value delivery in the process.
The primary reason teams miss commitments is that engineering operations rely on siloed data. You plan in one system and write code in another, so you never get a clear picture of actuals vs execution data. This fragmentation masks the true workflow friction draining your capacity and directly erodes trust in board-level reporting.
When your measurement systems are disconnected, your capacity planning becomes a guessing game. You see the cycle time increasing, but you can't see the underlying coordination breakdowns causing the delay.
Problem: Engineering managers struggle to reconcile their planning data with actual execution because standard tracking metrics in tools like Jira treat performance as isolated features.
Solution: The Jira velocity chart specifically tracks historical performance by displaying the number of story points completed in past sprints. Jira capacity planning is a separate function that calculates future availability based on user-entered schedules and hours. The critical difference is that both features rely entirely on manual inputs, so neither accounts for the actual code-level bottlenecks or real-time review delays happening in your version control system.
Modern software development has introduced a massive new variable to the capacity equation. Artificial intelligence coding assistants accelerate the initial drafting of code, which artificially inflates your team's velocity. A developer can generate hundreds of lines of logic in minutes.
But this AI code generation impact introduces a hidden drag on your actual capacity. High-complexity pull requests sit in the code review process for days because human reviewers struggle to validate large blocks of AI-generated logic. According to 2023 industry benchmarks from DevEx research, pull requests often sit idle for nearly 70 percent of their lifecycle. This PR review churn drains focus hours and causes multi-day PR delays, even while the team shows a "good" historical velocity on paper.
Your capacity planning must account for the reality of how enterprise engineering actually operates. Unplanned work and urgent incident responses consistently drain focus hours. Context switching between feature development and bug fixing destroys momentum. According to research from the American Psychological Association, shifting between complex tasks can cost up to 40 percent of a professional's productive time.
This friction multiplies when you factor in cross-team dependencies. A team might have the capacity to write the code, but they are blocked waiting on an API from another department. If you ignore these interruptions and the compounding weight of technical debt, your capacity plan is just a theoretical best-case scenario. This becomes especially critical during holiday weeks or major operational incidents, where actual capacity drops to a fraction of your standard baseline.
Standard measurement frameworks like DORA and SPACE provide valuable industry benchmarks. But they are only partial signals. They don't tell you that cycle time increased because three high-complexity, AI-generated PRs sat in review for four days due to a cross-team coordination breakdown.
The primary gap in delivery predictability is not a lack of metrics. The gap is a lack of operational intelligence connecting those metrics to actual execution. You need a unified data layer to see what is actually happening across Jira and GitHub so you can understand why execution stalls.
TargetBoard is an agentic operational intelligence platform that connects data across company systems, interprets performance through operational intelligence, and uses domain-expert AI agents to guide execution decisions. It bridges the gap between static planning metrics and actual delivery. TargetBoard’s domain-expert AI agents surface hidden workflow bottlenecks in real time. It acts as a systemic execution layer that explains why performance is changing, empowering leaders to make proactive decisions with absolute delivery confidence and align their engineering efforts with actual business outcomes.
Shifting your focus from outcome vs output requires a fundamental change in how you view engineering data. Agile velocity vs capacity is not just a math problem for your scrum masters to solve. It's a strategic framework for understanding your delivery predictability.
Understanding these patterns gives you a clear operational model for your next sprint planning session. Stop relying on lagging indicators to guess your future availability. Connect your planning data to your execution reality, identify the hidden friction draining your focus hours, and build a system that actually explains your engineering performance.

The dark side of measurement emerges when isolated metrics create a false sense of security. Teams naturally optimize for what leadership measures, so they inflate output numbers while ignoring the underlying bottlenecks that dictate true delivery speed.
I spoke with a VP of Engineering last quarter who experienced this firsthand during a major platform overhaul. Their DORA metrics looked perfect, and deployment frequency was at an all-time high. But the reality on the ground was a complete disaster.
The team was merging hundreds of tiny pull requests to keep velocity metrics green, while high-value features were trapped in endless review churn. This is the classic trap of watermelon dashboards. The reports look green on the outside, but they hide a deeply red execution reality on the inside.
A 2023 McKinsey analysis on developer productivity confirms that relying solely on isolated output metrics often masks the accumulation of technical debt, leading to accidental metric manipulation. Isolated metrics hide the actual complexity of the work, leading to missed deadlines.
Integrating data streams actively prevents these operational blind spots. A unified approach delivers specific advantages for leadership:
Enterprise software companies try to solve this trust crisis by purchasing a new visualization tool or building a massive data lake. They assume that routing all their disparate data into a single dashboard will magically create alignment.
But combining data is an institutional governance problem, not a simple routing issue. According to a 2022 Gartner study, nearly 60% of data integration projects fail to deliver business value because they focus purely on data movement rather than operational context.
Standard master data management (MDM) and data mining practices are technically sound, yet they fail to provide decision-grade reliability. A data warehouse can tell you that a Jira ticket took ten days to close.
It can't tell you that the ticket was delayed because AI-generated code introduced architectural complexity requiring three rounds of senior developer review. If your metrics don't reflect actual engineering workflows, your BI tools can't guide execution.
Building basic ETL pipelines only gives you faster access to the same disconnected metrics. True organizational alignment requires a system that interprets how a decision in one department impacts the delivery speed of another.
To make data-driven decisions, leaders must integrate critical business streams across the entire development lifecycle. The most common KPI data sources include project management platforms, code repositories, and customer support desks.
When you keep these disparate data sources isolated, they inherently conflict. Connecting them is the only way to build the contextual understanding required to spot trends before they derail a project. Integrating data streams across these three pillars provides a complete view of organizational performance.
Tools like Jira and Asana track the planned work and capacity allocation for your teams. They show you what engineering execution should look like in theory. But these systems often fail to capture hidden workflow bottlenecks, so leaders must cross-reference this planning data with actual code delivery metrics.
Platforms like GitHub house the actual reality of your software delivery. This is where you see the impact of AI-accelerated output and the hidden complexity it often introduces. Monitoring pull request size and review churn here reveals the technical debt accumulation that project management tools miss entirely.
Systems like Salesforce and Zendesk capture the downstream impact of your engineering decisions. They highlight operational friction and customer-reported defects. Relying on these tools in isolation creates attribution flaws, so you must connect support ticket volume back to specific code deployments to ensure accurate data validation.
Executives are tired of acting as human data routers. You spend hours interpreting disconnected charts just to guess why a project missed a deadline. To achieve true measurement authority, you must shift from passive dashboards to an active operational intelligence layer.
Implementing automated multi-source tracking provides distinct advantages for leadership teams:
Passive tools force you to interpret the data yourself. Modern execution requires systems that explain why the data is changing.
TargetBoard is an agentic operational intelligence platform that creates an intelligence layer between data systems and execution. It connects data across company systems, interprets performance continuously, and uses domain-expert AI agents to guide execution decisions. We don't just measure engineering performance. We explain why it's changing.
Mapping a single business outcome across multiple software systems proves the value of cross-system interpretation. Leaders can't fix a delivery bottleneck by looking at one tool in isolation. You must trace the delay directly to its root cause across your entire architecture to understand the real execution problem.
Consider a sudden spike in cycle time for a critical feature release. If you only look at your project management tool, you see a stalled ticket. That tells you nothing about the actual problem. But applying a cross-system framework makes the reality immediately clear.
First, your planning system flags the delayed initiative. Next, your code repository reveals that AI-generated code introduced massive structural complexity, resulting in high review churn. Finally, your delivery system shows that this specific complexity is causing deployment failures. Connecting KPIs from different data sources transforms a vague delay into a precise execution problem you can solve.
Achieving organizational alignment requires moving from disjointed reporting to a unified system that governs how performance is interpreted across the entire enterprise. You need a structured approach to build delivery confidence and establish a single source of truth. Keep in mind that frameworks like DORA or SPACE only provide signals rather than actual understanding.
In today's fast-paced business world, choosing the right technology solutions and vendors is more than just a matter of preference; it's a strategic decision that can significantly impact an organization's flexibility and growth. A critical factor in this decision-making process is the concept of vendor lock-in—the extent to which a company is tied to a specific vendor or product and the associated costs and complexities of switching to a different solution.
Many technology products today come with integrated Business Intelligence (BI) and reporting features. While these functionalities often seem beneficial at first glance, they can, paradoxically, limit a company's agility. By creating a dependency on these built-in tools, vendors make it challenging for companies to move away from their products, thus increasing the stickiness and dependency.Furthermore, the integration with third-party tools often involves pulling data into proprietary BI and analytics solutions, further entrenching organizations into the vendor's ecosystem. This integration can appear advantageous, but it often leads to a complex web of dependencies that can be costly and time-consuming to untangle.
TargetBoard offers a transformative solution to this common dilemma. By connecting to third-party systems, TargetBoard extracts and models data into our proprietary semantic layer. This process helps customers decouple their critical data from source systems, significantly reducing the risk of vendor lock-in.
1. Reduced Re-platforming Costs:
By simplifying the process of migrating data and systems, TargetBoard decreases the overall expenses associated with re-platforming projects.
2. Enhanced Data Lineage and Continuity:
Our approach ensures better tracking of data origin, movement, and transformation, providing businesses with a clearer understanding and greater control over their data assets.
3. KPI Stability and Reliability:
One of the most significant advantages of using TargetBoard is the assurance that key performance indicators (KPIs) remain consistent and reliable, even when there are changes or upgrades to underlying tools. This stability is crucial for businesses that rely on data-driven decision-making.
4. Superior Analytical Capabilities:
Beyond just preserving existing functionalities, TargetBoard enhances the analytical capabilities available to businesses, often surpassing what is offered by the source systems themselves.
TargetBoard stands out for its effortless integration, regardless of your stage in the vendor migration process. Whether you're planning a transition or have already moved, incorporating TargetBoard is straightforward, risk-free, and requires minimal effort. Our platform is tailored to blend into your existing systems smoothly, allowing you to quickly benefit from uninterrupted KPI continuity, without disrupting your business operations.
In conclusion, TargetBoard empowers organizations to take control of their technology choices. By providing a way to easily extract and utilize data independent of the underlying systems, we help businesses avoid the pitfalls of vendor lock-in, ensuring they remain agile, data-savvy, and competitive in an ever-evolving market landscape.

.png)



