


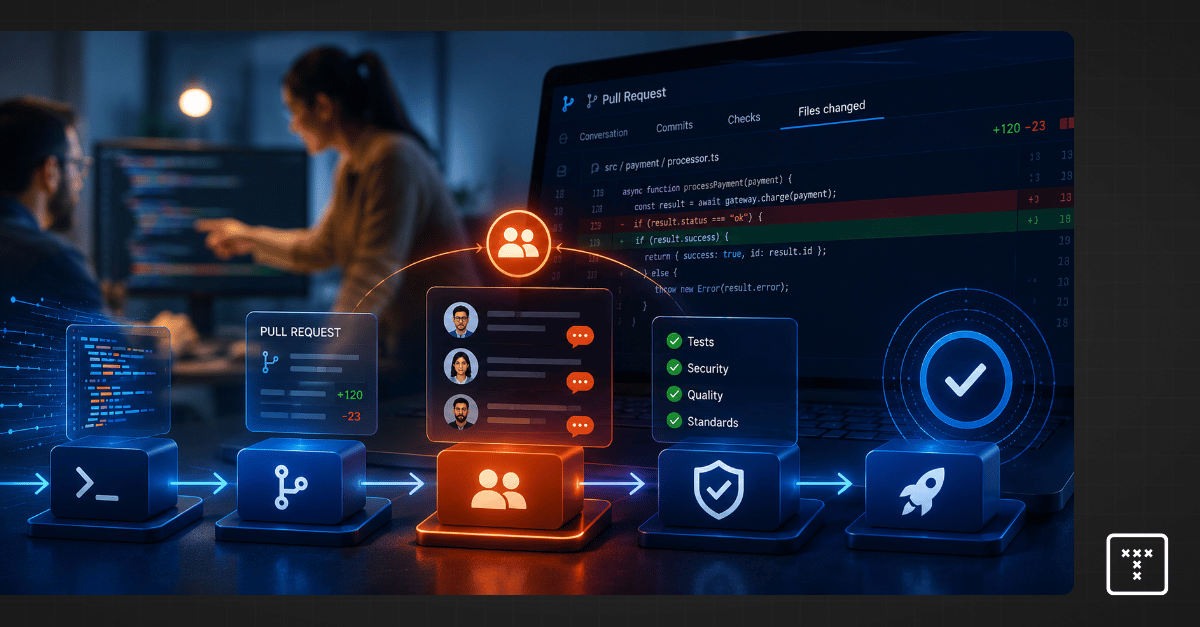
A good code review process functions like a smooth traffic system rather than a rigid tollbooth. When engineering executives ask how to do a code review at scale, they often mistakenly push developers to review code faster. That approach fails because it ignores the underlying workflow physics.
A mature code review process limits work-in-progress, automates syntax checks, and explicitly unblocks cross-team dependencies. This operational shift guarantees delivery predictability by keeping work moving efficiently through the pipeline.
To scale a peer code review system, you must stop managing individuals and start managing the system constraints. Peer review breaks down completely when treated as a behavioral checklist.
We have all seen the immediate output boost from AI coding assistants. But this massive surge in AI-generated code fundamentally breaks traditional human-dependent review bottlenecks. Human review capacity remains entirely static, so the exponential increase in code volume clogs the pipeline. This AI impact forces engineering leaders to rethink how inspection works at scale.
Engineering teams are shipping more pull requests than ever before. This looks like a massive productivity win on a static dashboard. But the reality introduces severe operational risk.
AI models can generate structurally plausible code that harbors deep hidden complexity. Reviewers facing a massive backlog often skim these large changelists because they lack the time to inspect every line. This allows technical debt to enter the system silently, which degrades long-term code maintainability and slows down future development.
When code volume surges and complexity rises, review dependencies naturally centralize. Teams unconsciously route the most difficult pull requests to a few highly trusted engineers. These "hero" engineers quickly become single points of failure.
They hold up dozens of tasks while trying to protect the system architecture from instability. Traditional metrics will show cycle times slowing down across the board, but they completely fail to explain that this centralization is the root cause. You need objective operational data to unblock these dependencies without resorting to micromanagement.
Transforming your pipeline requires objective rules that govern how work moves through the system. Implementing the best practices for peer code review means setting boundaries that protect engineering throughput and guarantee delivery predictability.
To review code effectively at scale, follow these seven operational steps:
A comprehensive SmartBear study shows that defect discovery rates drop significantly when pull requests exceed 200 to 400 lines of code. You must enforce strict PR size limits to keep batches small and readable. Combining this with rigid work-in-progress limits prevents massive code dumps from clogging the review queue and stalling the entire team.
Reviewers waste hours trying to reverse-engineer the intent behind a code change. Mandate strict commit message formatting and standard code review checklists so reviewers never have to guess the intent behind a code change. Providing this automated context ensures the reviewer understands the strategic goal before they read a single line of code.
Establish inspection rate limits of 60 to 90 minutes per session as a general guideline because human cognitive focus degrades rapidly during highly detailed tasks. Treating this timeframe as a strict boundary maintains a high defect discovery rate and protects your team from review notification fatigue.
Human reviewers should never argue about spacing or variable naming. Continuous Integration pipelines and automated linters must handle all formatting rules. Automating these checks eliminates subjective review decisions and reserves human attention for architectural edge cases where automated tools fail.
Vague expectations destroy software delivery performance. Define exact code quality baselines at the system level so reviewers can evaluate changes against objective operational signals rather than inconsistent developer etiquette.
Infinite asynchronous feedback loops kill momentum. When a pull request hits three rounds of comments, you must trigger a mandatory synchronous communication escape. Shifting from async PR churn to a quick five-minute video call resolves misunderstandings instantly and gets the code merged.
Requiring a single principal engineer to approve every change creates massive delays. Update your codeowners configurations to distribute review responsibilities across multiple qualified peers, which instantly unblocks cross-team dependencies and keeps teams focused on shipping.
You can't fix a slow pipeline by asking developers to work harder. Pushing teams to review faster is a common executive mistake that completely ignores the root cause of the delay. You make the process easier by reducing the cognitive load required to approve a change and fixing the system workflow. High review churn usually indicates a breakdown in requirements rather than a lack of coding skill.
Leaders must deploy operational intelligence to identify exactly where these breakdowns occur. When you track the specific stage where a ticket stalls, you can adjust the workflow to restore a predictable sprint velocity.
The 80/20 rule in coding dictates that 80 percent of your value comes from 20 percent of your effort. Apply this exact principle to your review pipelines so reviewers spend 80 percent of their time analyzing the 20 percent of the codebase that carries the highest risk.
You have to accept deliberate delivery tradeoffs. Not every internal script requires the same rigorous inspection as your core payment gateway. Focusing human effort on high-risk areas protects long-term code maintainability and ensures that necessary refactoring does not derail your primary delivery goals.
Standard DORA metrics provide lagging indicators of software delivery performance. They tell you that cycle time is slowing down, but they completely fail to explain why the delay is happening. When you rely solely on these static dashboards, you lack the objective operational signals needed to make confident decisions.
To actually unblock your pipeline, you need to see the hidden dependencies. TargetBoard is an agentic operational intelligence platform that helps leadership teams understand how execution is performing, why it is changing, and how to respond. It connects data across company systems, interprets performance through operational intelligence, and uses domain-expert AI agents to guide execution decisions.
While a traditional dashboard shows a delayed sprint, TargetBoard's AI agents quantify Artificial Intelligence-generated versus human code. They uncover hidden single points of failure and highlight workflow breakdowns in real-time. This translates raw data into actionable insights so leaders can make data-driven decisions to unblock their pipelines.
Understanding the difference between passive tracking and active intelligence is the key to scaling your engineering organization.
Mastering code review best practices means shifting your perspective from individual behavior to system design. You now have a clear framework to enforce work-in-progress limits, automate context, and decentralize review dependencies.
Applying these principles protects your engineering throughput from the massive volume of AI-generated code. Start by auditing your current inspection rate limits and identifying any hidden "hero" engineers in your pipeline, since removing those single points of failure immediately stabilizes delivery predictability and gives your team the autonomy they need to ship with confidence.
.png)
The best KPI examples for engineering span four core categories that measure speed, efficiency, quality, and system health. Tracking only one category leads to broken systems. Optimizing for speed without monitoring quality will inevitably create technical debt and delivery bottlenecks.
Here are the core engineering metrics you need to track software delivery performance accurately.
Google's DevOps Research and Assessment (DORA) metrics are the baseline industry standard for measuring delivery performance. They focus strictly on how fast you ship and how reliable those shipments are.
Speed metrics tell you when code ships. Efficiency metrics reveal how work flows through your internal systems before deployment.
Shipping fast only matters if you ship reliable code that solves customer problems. You must connect engineering output to actual business value.
A fast team will eventually slow down if the underlying system is fragile. These metrics ensure sustainable developer productivity and long-term codebase viability.
Standard metrics like cycle time are just symptoms. They tell you a delay happened. They don't perform root cause analysis for you.
When a sprint fails, the dashboard might show a drop in velocity. The actual cause could be unmapped cross-team dependencies or severe coordination breakdowns. Relying purely on symptom metrics without understanding the underlying workflow creates massive execution risks.
Some leaders try to optimize performance by tracking individual developer output, like lines of code or commits to production. This is a critical operational mistake. Measuring individual output creates toxic gamification because it incentivizes the wrong behaviors:
You should measure systems and workflows. You should never measure individuals.
The integration of artificial intelligence code generation fundamentally breaks traditional measurement models. An AI coding assistant can generate hundreds of lines of code in seconds. Your sprint velocity might look incredible on paper as output soars.
In reality, that massive volume of code introduces hidden complexity. Reviewers can't process the influx of AI-generated code fast enough. This causes pull requests to stall and review times to spike. When reviewers inevitably rush to clear the backlog, defects slip into production.
This creates a vicious cycle of high code churn and massive code rework. Your metrics show high output, yet your actual delivery grinds to a halt. Traditional metrics measure the volume of code, so they completely miss the risk that AI introduces into the system.
When velocity drops during agile sprints, you need a systematic way to find the root cause. Pushing the team to work harder will only compound the problem.
Building a balanced measurement system requires more than just connecting tools to a dashboard. You need to align your engineering metrics with your actual delivery workflows to capture accurate signals without creating administrative overhead.
Follow these steps to build a system that measures the entire software delivery lifecycle.
Standard metrics like cycle time and deployment frequency are just passive signals. They tell you what happened, but they completely fail to explain why it happened.
The real problem engineering leaders face is understanding why velocity drops or pull requests stall. This gap becomes critical when Artificial Intelligence accelerates raw output but increases hidden complexity. You have dashboards full of kpis for engineering teams, yet you still lack the context to diagnose the root causes of delivery delays. You are measuring the symptoms of execution risks without understanding the underlying workflow behaviors.
Frameworks provide signals. They don't provide understanding. Tracking KPIs is only step one. Step two is moving beyond passive dashboards to an operational intelligence layer that connects data across systems to explain why metrics are shifting.
TargetBoard is an agentic operational intelligence platform that helps leadership teams understand how execution is performing, why it is changing, and how to respond. TargetBoard's domain-expert Artificial Intelligence agents connect data across your planning, code, and delivery systems.
This gives you the system-level visibility needed to explain metric shifts and confidently guide execution decisions. You stop guessing why performance changed and start addressing the hidden complexities slowing your teams down.
Understanding these patterns gives you a clear framework to align your teams and predictably scale your software delivery. You now have the vocabulary and methods to look past basic engineering KPIs and diagnose the actual workflows driving them.
Stop relying on performance KPIs for engineering that measure output without context. Start connecting your data across systems to expose hidden bottlenecks and prioritize actual improvements. When you move from passive measurement to active understanding, you regain the confidence to make critical delivery decisions.

You just walked out of a board meeting where the CEO asked for hard numbers to justify engineering headcount. They want a simple metric to show how productive your teams are.
But you know that implementing toxic tracking systems ruins engineering culture and provides weak execution signals. The problem is that your data is trapped in silos across Jira and GitHub.
You can see that cycle time is increasing, but you lack the context to explain why it's happening. You need a defensible framework that satisfies executive reporting requirements while protecting your teams.
The goal is to move past passive reporting and build an operational intelligence layer that actively governs execution decisions.
If you want to understand how to measure developer productivity effectively, engineering leaders must shift from tracking individual output to analyzing systemic execution. The right approach combines behavioral telemetry with qualitative insights to understand how work actually flows through the organization.
The pressure to demonstrate engineering performance often leads organizations to pick the easiest data points available. Tracking lines of code or story points completely misses the reality of how software is built¹.
Measuring developer productivity requires focusing on execution signals that actually correlate with business outcomes. You have to evaluate output vs. outcomes to ensure your teams are building the right things efficiently.
A true KPI for a software developer isn't an individual metric but a team-level indicator of speed, quality, and workflow efficiency.
Consulting firms often push for individual contribution metrics to identify low performers. Despite this pressure, stack-ranking developers based on commit counts is a universally detrimental practice that ruins engineering culture².
When you measure individuals, developers chase the metric by taking easy tickets and avoiding complex collaborative work. This creates a system where high velocity actually masks a high accumulation of technical debt.
Focusing on team-level outcomes forces everyone to prioritize the actual delivery of the product.
The rise of AI coding tools has completely broken traditional measurement systems. AI impact isn't just about writing code faster.
These tools artificially inflate raw output and commit counts, but they secretly increase code review wait times. A developer might use AI-generated code to finish a feature in two hours instead of two days.
That massive block of code then sits in a review queue for four days because peers struggle to understand the hidden technical debt and code complexity it introduces. The raw output looks fantastic on a dashboard, so the actual delivery system slows down unnoticed.
Standard industry frameworks provide highly valuable baseline signals for your engineering organization. They give you a structured way to look at developer productivity metrics and establish performance baselines.
Just remember that these frameworks provide signals rather than systemic understanding. They act like a check-engine light for your delivery predictability. You still need operational intelligence to diagnose the actual engine.
The DevOps Research and Assessment team established the industry standard for measuring software delivery performance. These metrics focus strictly on the speed and stability of your Continuous Integration and Continuous Deployment pipelines.
Flow metrics help you understand the friction inside your delivery workflows. They track how work moves from the first commit to the final release.
Cycle time is the most critical metric here because it measures the total time a team spends working on an issue. You must break cycle time down to find the actual workflow bottlenecks.
High cycle times are usually driven by pull request size and excessive review time. When pull requests are too large, wait time increases as reviewers delay the complex task.
Tracking throughput helps you see the volume of work completed, so monitoring review wait times tells you where the system is actually stalling³.
Quantitative metrics only tell half the story. The Satisfaction, Performance, Activity, Communication, Efficiency framework introduces qualitative data to your measurement strategy.
It connects developer satisfaction directly to hard business return on investment. Attitudinal data captures how developers feel about their tooling and processes, while behavioral telemetry tracks what they actually do⁴.
High developer experience scores correlate strongly with low engineering drag and high retention. If your developers are constantly fighting broken environments, their satisfaction drops long before your cycle time increases.
According to benchmark reports from McKinsey and GitHub, teams with high satisfaction scores consistently deliver more reliable code⁵.
Standard frameworks are incredibly useful for setting baselines, but they stop short of solving the actual problem. A common leadership mistake is treating these operational metrics as a complete diagnostic tool rather than just a check-engine light.
When your lead time for changes spikes, the dashboard tells you that a problem exists. It doesn't tell you how to fix it.
This disconnect happens because your execution data lives in disconnected silos. Planning data sits in Jira, code data lives in GitHub, and deployment data resides in your delivery workflows.
This fragmentation creates engineering drag because leaders have to manually piece together what is actually happening. You must move past simply observing metric signals and start building a systemic understanding of how your teams operate.
When a top-level metric shifts, you have to know exactly where to look for the root cause. This requires mapping your quantitative signals directly to the daily habits of your engineering teams.
Connecting these data points enables active decision-making instead of reactive panic.
The fundamental flaw with traditional dashboards is that they measure the output, but an operational intelligence layer measures the systemic context of that output. Dashboards count how many pull requests were merged.
System-level visibility tells you if those pull requests actually moved the business forward or just created future maintenance burdens.
Relying purely on standard telemetry leads to a false sense of security. You might see high commit volumes and assume your teams are highly productive.
Without the context of code complexity and review wait times, you can't see that those commits are actually introducing risk into the system. You have to connect your planning, code, and delivery data to see the true flow of work.
Standard frameworks provide valuable signals, yet they can't explain why performance is changing. This limitation is becoming a critical failure point right now because AI is accelerating raw output and clogging your review pipelines.
Your developers are writing code faster than ever, so that speed is introducing hidden complexity and risk into your delivery systems. Traditional metrics are breaking down under this new reality.
This is exactly why engineering leaders must evolve from passive measurement to an active operational intelligence layer. TargetBoard is an agentic operational intelligence platform designed specifically to solve this systemic gap.
We don't just measure engineering performance. We explain why it's changing. The platform connects planning, code, and delivery data across your existing silos to surface hidden risks before they slow down your teams.
Instead of forcing you to interpret static charts, the platform uses domain-expert AI agents to continuously analyze your research and development execution. These agents monitor your domains for bottlenecks, review churn, and AI-generated code complexity.
This provides the code review intelligence required to flag high-risk pull requests before they merge, giving you true system-level visibility so you can optimize resource allocation and make active decision-making a daily reality. You stop reacting to delayed metric drops and start governing your execution with confidence.
Measuring developer productivity is ultimately about ensuring sustainable development and proving a tangible ROI to your business. You can't achieve this by counting lines of code or stack-ranking your engineers.
You have to measure how effectively your entire system delivers value to the customer.
Keep in mind that implementing systemic measurement takes time and requires a deliberate culture shift. You have to train your managers to look at workflow behaviors instead of individual output.
When you connect your fragmented data and focus on team-level outcomes, you empower your engineering organization to align, prioritize, and ship with absolute predictability.

Operational waste is the non-product output generated during daily business operations, widely recognized as a silent profit killer that drains time and resources. But for modern software teams, this waste is rarely physical scrap. Instead, it manifests as:
These invisible bottlenecks silently kill true productivity, consuming engineering hours without moving product features forward.
Traditional management frameworks track physical materials and visible process inefficiencies. Modern engineering leaders must track behavioral friction and organizational latency. If you apply manufacturing metrics to digital delivery systems, you will measure output while completely missing system-level visibility.
The reality of your execution pipeline is that waste happens between active work states. Context switching forces developers to abandon deep work to track down missing requirements across fragmented data systems. Review congestion leaves critical pull requests sitting untouched for days.
Handoff friction occurs when silos prevent clear communication between QA, product, and engineering. You might track high team activity across your dashboards, but you still experience slow delivery because waiting systems dominate the cycle.
Artificial intelligence fundamentally changes software development by accelerating code generation. This dramatically increases raw output, but without proper governance it floods your pipeline. This surge introduces hidden complexity and spikes pull request churn across your organization.
Human reviewers can't keep up with the sheer volume of generated code. This creates massive review system inefficiency and severe code review bottlenecks. You end up with more code but slower predictable delivery, so the tool built to increase speed actually compounds your operational waste.
Lean manufacturing defines seven traditional operational wastes, but you must translate these into software delivery equivalents to govern modern teams. Overproduction is no longer excess inventory. It's scope creep and unused materials in your codebase. Defects translate directly to technical debt, and waiting translates to code review bottlenecks.
Industry standard frameworks like DORA metrics and the SPACE framework provide valuable signals for engineering leaders. Tracking deployment frequency and lead time establishes a critical baseline for software delivery performance^1. Similarly, measuring developer activity alongside system reliability provides a broader view of team health^2.
But these only offer lagging indicators of performance. They tell you that a delivery metric shifted, yet they completely fail to explain the root cause.
When your cycle time spikes, a traditional dashboard flags the delay. It doesn't tell you that specific high-complexity pull requests have been sitting in review for days. You see the symptom but miss the workflow friction. To achieve true productivity, you must upgrade your tooling to capture the behavioral context behind the numbers.
Identifying and eliminating workflow friction requires you to move beyond static manual reporting. You have to implement an operational intelligence layer that catches delivery risk exactly when decisions are made. This is where you replace fragmented data silos with system-level understanding.
TargetBoard is an agentic operational intelligence platform that connects data across company systems, interprets performance through operational intelligence, and uses domain-expert artificial intelligence agents to guide execution decisions. These agents continuously analyze performance across GitHub, Jira, and your delivery tools.
This agentic analysis detects review bottlenecks instantly and surfaces delivery risks before they compound into missed milestones. By providing decision-ready inputs directly to your engineering managers, you drastically reduce operational overhead. You shift your entire management posture from reactive intuition to proactive bottleneck identification.
The most successful engineering leaders actively govern their workflows to reduce coordination drag. You must shift your strategy from tracking raw output to managing system-level friction. This allows you to align your teams and prioritize the work that actually drives business value.
When you reduce invisible waiting systems, you can ship faster without accumulating technical debt. This focus on execution alignment ensures you maintain sustainable development across your entire organization. You can finally monitor maintainability trends and catch rework patterns before they destroy your predictable delivery timelines.

.webp)



