



Serendipity, the occurrence and development of events by chance in a happy or beneficial way, is a cornerstone of innovation. It requires the right conditions to manifest, and when it does, it can lead to groundbreaking discoveries and improvements.
In data-driven management, serendipity translates into uncovering new and exciting insights that can propel a business forward. These insights can range from novel methods to reduce costs, boost sales, enhance performance, or even integrate new data sources that deepen our understanding. The essence of serendipity lies in finding and leveraging significant nuggets of information that were previously hidden.
To foster serendipity, the right people need to be in the right place at the right time, equipped with the right mindset. They must be motivated, focused on achieving their goals, and able to ideate, experiment, and execute without barriers or friction.
Allow us to share two recent meetings that illustrate the impact of serendipity in analytics:
In a conversation with a C-level executive from a mid-sized enterprise (3,000 employees), he shared a frustrating reality: every time he had a data-related question, it took up to six months to get an answer. This prolonged timeline was due to a convoluted process involving multiple stages and people, each with a narrow understanding of the original intent. It resembled a game of "Chinese whispers," where the message gets distorted along the way. The teams involved lacked the domain expertise and context needed to provide swift and accurate insights. In such an environment, serendipity and innovation are stifled. Management is left to make decisions based on limited resources and insights, constrained by the time-consuming process.
In contrast, a Senior Director from another tech organization (1,500 employees) shared a different story. They had adopted TargetBoard to replace their traditional data team, empowering managers directly. Weekly meetings with this organization are a testament to the power of serendipity. Every week, new and interesting insights emerge, leading to actionable improvements for the business. The cost of testing or making changes is nearly zero, and results are instantaneous. By connecting domain experts with the data they need through a frictionless tool, barriers are removed, allowing innovative ideas to flourish.
One example from our last meeting stands out: “Hey, you know what would be really cool? If we could see a metric of Cycle Time divided by estimated Story Points. This would allow me to finally normalize the velocity between all our teams.” With TargetBoard, such ideas are not only possible but easy to implement.
TargetBoard is on a mission to democratize decision-making for managers. We are fortunate to have amazing partners who share our vision. By removing barriers and providing the right tools, we enable serendipity to thrive, leading to continuous innovation and improvement.
In conclusion, serendipity analytics is about creating the conditions where chance discoveries can lead to significant business advancements. By empowering managers with the right tools and fostering an environment of experimentation and swift execution, TargetBoard helps turn serendipitous moments into strategic advantages.
In the dynamic world of business, the ability to swiftly and accurately access comprehensive data is not just advantageous – it’s imperative. Whether it's a venture capitalist assessing a potential investment, a company navigating an acquisition, or an executive crafting a strategic "30-60-90" plan, the common denominator remains: the need for rapid, reliable, and thorough data insights. Traditional methods of data analysis, while thorough, often fall short in terms of efficiency and speed. This is where TargetBoard revolutionizes the game.
For Investors and M&A Events: In high-stakes scenarios like investments or mergers and acquisitions, due diligence is crucial. Stakeholders require full access to a company’s performance KPIs to make informed decisions. The traditional approach, relying on analysts and extensive reports, is time-consuming and can delay critical decisions.
For New Managers and Executives: Executives stepping into new roles need a quick, accurate understanding of their operational landscape to formulate effective “30-60-90” plans. These plans must be grounded in real data and measurable targets to set the stage for success.
Traditional Approach
Typically involves assembling a team of analysts to compile and assess necessary data points. This process, from data collection to quality assessment, can span weeks, delaying decision-making and increasing overhead.
The TargetBoard Advantage
TargetBoard dramatically simplifies this process. With TargetBoard, you gain access to all necessary company data and analytics within minutes. The key benefits include:
- Complete and Comprehensive Data: Access a holistic view of a company's performance metrics quickly.
- Trusted, Verifiable Accuracy: Confidence in data accuracy ensures that strategic plans are based on solid foundations.
- Rapid Insights: Shift from weeks of analysis to instant data accessibility, accelerating the decision-making process.
- Reduced Overhead: Minimize distractions for your team, allowing them to focus on core activities instead of lengthy data compilation and analysis.
TargetBoard not only provides a solution for rapid data access but redefines how businesses approach strategic planning and decision-making. Its intuitive design and powerful analytics tools mean that comprehensive, accurate data is no longer a bottleneck in the decision-making process, but a powerful catalyst for strategic action. Whether it’s evaluating a potential investment or stepping confidently into a new executive role, TargetBoard ensures that your decisions are informed, timely, and backed by the best data available.
In the modern business landscape, where time is as valuable as information, TargetBoard stands as an essential tool for efficient, data-driven decision-making. It's more than just a platform; it's a strategic partner that empowers businesses to make informed decisions swiftly and confidently. Embrace the future of business analysis with TargetBoard – where data, speed, and accuracy converge.
Effective project management is crucial, especially for tech startups in their growth stage. Despite its importance, many companies overlook this aspect, often entrusting product or development managers with the task without specialized support. This approach, however, overlooks the complexities involved in tracking Key Performance Indicators (KPIs) of a project.
KPIs are essential for measuring the success and efficiency of a project. However, tracking these metrics can be challenging. Data availability, accuracy, and timeliness are common issues. Moreover, companies often recognize the need for KPI tracking after a project has already commenced, leading to retroactive planning and data collection.
A significant consequence of not tracking project KPIs effectively is the lack of visibility into a project's progress. This opacity creates friction among management team members and leads to a considerable waste of time. Managers often find themselves in a constant hustle to compile and present KPIs ad-hoc, multiple times a day. This process not only consumes valuable time but also impedes efficient communication within the team.
In the realm of project management, several KPIs are crucial for monitoring progress and success. These include:
1. Project Completion Rate: Measures the percentage of projects completed within the stipulated timeframe.
2. Budget Variance: Tracks the difference between the budgeted and actual cost of the project.
3. Scope Creep: Monitors any changes or expansions in project scope beyond the original plan.
4. Resource Utilization: Assesses how efficiently resources (both human and material) are used.
5. Milestone Achievement: Tracks the completion of key stages within the project timeline.6. Team Performance: Evaluates the productivity and efficiency of the team members.
Managing multiple projects adds further complexity. Each project may have different KPIs and tracking requirements, making a unified system like TargetBoard essential for coherent and efficient management.
TargetBoard simplifies the process of tracking these KPIs. It integrates seamlessly with existing systems, providing immediate and hassle-free access to essential project metrics. This accessibility is crucial for making informed decisions and keeping projects on track.
TargetBoard is designed to be adaptable. It can be used at any stage of a project, allowing for retroactive data filling and redefining project scopes based on accurate, up-to-date information.Tracking KPIs is a fundamental part of successful project management. TargetBoard offers a streamlined, comprehensive solution, ensuring that project managers have the data they need to guide their projects to successful completion. This tool is indispensable for companies aiming to enhance their project management capabilities and achieve better outcomes.
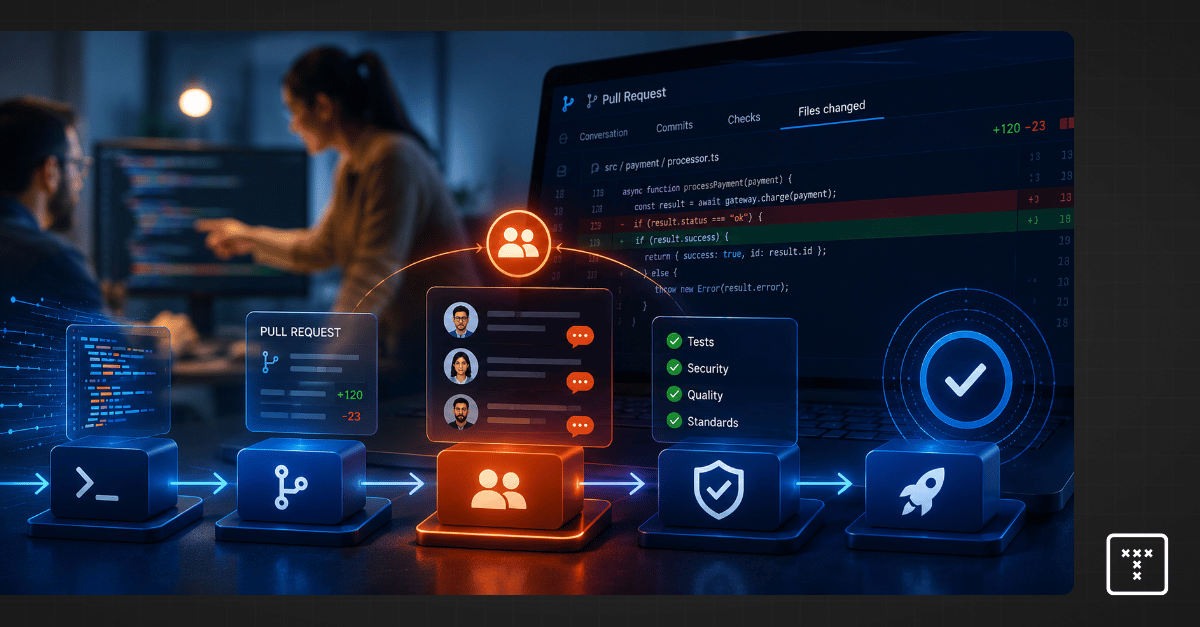
A good code review process functions like a smooth traffic system rather than a rigid tollbooth. When engineering executives ask how to do a code review at scale, they often mistakenly push developers to review code faster. That approach fails because it ignores the underlying workflow physics.
A mature code review process limits work-in-progress, automates syntax checks, and explicitly unblocks cross-team dependencies. This operational shift guarantees delivery predictability by keeping work moving efficiently through the pipeline.
To scale a peer code review system, you must stop managing individuals and start managing the system constraints. Peer review breaks down completely when treated as a behavioral checklist.
We have all seen the immediate output boost from AI coding assistants. But this massive surge in AI-generated code fundamentally breaks traditional human-dependent review bottlenecks. Human review capacity remains entirely static, so the exponential increase in code volume clogs the pipeline. This AI impact forces engineering leaders to rethink how inspection works at scale.
Engineering teams are shipping more pull requests than ever before. This looks like a massive productivity win on a static dashboard. But the reality introduces severe operational risk.
AI models can generate structurally plausible code that harbors deep hidden complexity. Reviewers facing a massive backlog often skim these large changelists because they lack the time to inspect every line. This allows technical debt to enter the system silently, which degrades long-term code maintainability and slows down future development.
When code volume surges and complexity rises, review dependencies naturally centralize. Teams unconsciously route the most difficult pull requests to a few highly trusted engineers. These "hero" engineers quickly become single points of failure.
They hold up dozens of tasks while trying to protect the system architecture from instability. Traditional metrics will show cycle times slowing down across the board, but they completely fail to explain that this centralization is the root cause. You need objective operational data to unblock these dependencies without resorting to micromanagement.
Transforming your pipeline requires objective rules that govern how work moves through the system. Implementing the best practices for peer code review means setting boundaries that protect engineering throughput and guarantee delivery predictability.
To review code effectively at scale, follow these seven operational steps:
A comprehensive SmartBear study shows that defect discovery rates drop significantly when pull requests exceed 200 to 400 lines of code. You must enforce strict PR size limits to keep batches small and readable. Combining this with rigid work-in-progress limits prevents massive code dumps from clogging the review queue and stalling the entire team.
Reviewers waste hours trying to reverse-engineer the intent behind a code change. Mandate strict commit message formatting and standard code review checklists so reviewers never have to guess the intent behind a code change. Providing this automated context ensures the reviewer understands the strategic goal before they read a single line of code.
Establish inspection rate limits of 60 to 90 minutes per session as a general guideline because human cognitive focus degrades rapidly during highly detailed tasks. Treating this timeframe as a strict boundary maintains a high defect discovery rate and protects your team from review notification fatigue.
Human reviewers should never argue about spacing or variable naming. Continuous Integration pipelines and automated linters must handle all formatting rules. Automating these checks eliminates subjective review decisions and reserves human attention for architectural edge cases where automated tools fail.
Vague expectations destroy software delivery performance. Define exact code quality baselines at the system level so reviewers can evaluate changes against objective operational signals rather than inconsistent developer etiquette.
Infinite asynchronous feedback loops kill momentum. When a pull request hits three rounds of comments, you must trigger a mandatory synchronous communication escape. Shifting from async PR churn to a quick five-minute video call resolves misunderstandings instantly and gets the code merged.
Requiring a single principal engineer to approve every change creates massive delays. Update your codeowners configurations to distribute review responsibilities across multiple qualified peers, which instantly unblocks cross-team dependencies and keeps teams focused on shipping.
You can't fix a slow pipeline by asking developers to work harder. Pushing teams to review faster is a common executive mistake that completely ignores the root cause of the delay. You make the process easier by reducing the cognitive load required to approve a change and fixing the system workflow. High review churn usually indicates a breakdown in requirements rather than a lack of coding skill.
Leaders must deploy operational intelligence to identify exactly where these breakdowns occur. When you track the specific stage where a ticket stalls, you can adjust the workflow to restore a predictable sprint velocity.
The 80/20 rule in coding dictates that 80 percent of your value comes from 20 percent of your effort. Apply this exact principle to your review pipelines so reviewers spend 80 percent of their time analyzing the 20 percent of the codebase that carries the highest risk.
You have to accept deliberate delivery tradeoffs. Not every internal script requires the same rigorous inspection as your core payment gateway. Focusing human effort on high-risk areas protects long-term code maintainability and ensures that necessary refactoring does not derail your primary delivery goals.
Standard DORA metrics provide lagging indicators of software delivery performance. They tell you that cycle time is slowing down, but they completely fail to explain why the delay is happening. When you rely solely on these static dashboards, you lack the objective operational signals needed to make confident decisions.
To actually unblock your pipeline, you need to see the hidden dependencies. TargetBoard is an agentic operational intelligence platform that helps leadership teams understand how execution is performing, why it is changing, and how to respond. It connects data across company systems, interprets performance through operational intelligence, and uses domain-expert AI agents to guide execution decisions.
While a traditional dashboard shows a delayed sprint, TargetBoard's AI agents quantify Artificial Intelligence-generated versus human code. They uncover hidden single points of failure and highlight workflow breakdowns in real-time. This translates raw data into actionable insights so leaders can make data-driven decisions to unblock their pipelines.
Understanding the difference between passive tracking and active intelligence is the key to scaling your engineering organization.
Mastering code review best practices means shifting your perspective from individual behavior to system design. You now have a clear framework to enforce work-in-progress limits, automate context, and decentralize review dependencies.
Applying these principles protects your engineering throughput from the massive volume of AI-generated code. Start by auditing your current inspection rate limits and identifying any hidden "hero" engineers in your pipeline, since removing those single points of failure immediately stabilizes delivery predictability and gives your team the autonomy they need to ship with confidence.
.png)
The best KPI examples for engineering span four core categories that measure speed, efficiency, quality, and system health. Tracking only one category leads to broken systems. Optimizing for speed without monitoring quality will inevitably create technical debt and delivery bottlenecks.
Here are the core engineering metrics you need to track software delivery performance accurately.
Google's DevOps Research and Assessment (DORA) metrics are the baseline industry standard for measuring delivery performance. They focus strictly on how fast you ship and how reliable those shipments are.
Speed metrics tell you when code ships. Efficiency metrics reveal how work flows through your internal systems before deployment.
Shipping fast only matters if you ship reliable code that solves customer problems. You must connect engineering output to actual business value.
A fast team will eventually slow down if the underlying system is fragile. These metrics ensure sustainable developer productivity and long-term codebase viability.
Standard metrics like cycle time are just symptoms. They tell you a delay happened. They don't perform root cause analysis for you.
When a sprint fails, the dashboard might show a drop in velocity. The actual cause could be unmapped cross-team dependencies or severe coordination breakdowns. Relying purely on symptom metrics without understanding the underlying workflow creates massive execution risks.
Some leaders try to optimize performance by tracking individual developer output, like lines of code or commits to production. This is a critical operational mistake. Measuring individual output creates toxic gamification because it incentivizes the wrong behaviors:
You should measure systems and workflows. You should never measure individuals.
The integration of artificial intelligence code generation fundamentally breaks traditional measurement models. An AI coding assistant can generate hundreds of lines of code in seconds. Your sprint velocity might look incredible on paper as output soars.
In reality, that massive volume of code introduces hidden complexity. Reviewers can't process the influx of AI-generated code fast enough. This causes pull requests to stall and review times to spike. When reviewers inevitably rush to clear the backlog, defects slip into production.
This creates a vicious cycle of high code churn and massive code rework. Your metrics show high output, yet your actual delivery grinds to a halt. Traditional metrics measure the volume of code, so they completely miss the risk that AI introduces into the system.
When velocity drops during agile sprints, you need a systematic way to find the root cause. Pushing the team to work harder will only compound the problem.
Building a balanced measurement system requires more than just connecting tools to a dashboard. You need to align your engineering metrics with your actual delivery workflows to capture accurate signals without creating administrative overhead.
Follow these steps to build a system that measures the entire software delivery lifecycle.
Standard metrics like cycle time and deployment frequency are just passive signals. They tell you what happened, but they completely fail to explain why it happened.
The real problem engineering leaders face is understanding why velocity drops or pull requests stall. This gap becomes critical when Artificial Intelligence accelerates raw output but increases hidden complexity. You have dashboards full of kpis for engineering teams, yet you still lack the context to diagnose the root causes of delivery delays. You are measuring the symptoms of execution risks without understanding the underlying workflow behaviors.
Frameworks provide signals. They don't provide understanding. Tracking KPIs is only step one. Step two is moving beyond passive dashboards to an operational intelligence layer that connects data across systems to explain why metrics are shifting.
TargetBoard is an agentic operational intelligence platform that helps leadership teams understand how execution is performing, why it is changing, and how to respond. TargetBoard's domain-expert Artificial Intelligence agents connect data across your planning, code, and delivery systems.
This gives you the system-level visibility needed to explain metric shifts and confidently guide execution decisions. You stop guessing why performance changed and start addressing the hidden complexities slowing your teams down.
Understanding these patterns gives you a clear framework to align your teams and predictably scale your software delivery. You now have the vocabulary and methods to look past basic engineering KPIs and diagnose the actual workflows driving them.
Stop relying on performance KPIs for engineering that measure output without context. Start connecting your data across systems to expose hidden bottlenecks and prioritize actual improvements. When you move from passive measurement to active understanding, you regain the confidence to make critical delivery decisions.

You just walked out of a board meeting where the CEO asked for hard numbers to justify engineering headcount. They want a simple metric to show how productive your teams are.
But you know that implementing toxic tracking systems ruins engineering culture and provides weak execution signals. The problem is that your data is trapped in silos across Jira and GitHub.
You can see that cycle time is increasing, but you lack the context to explain why it's happening. You need a defensible framework that satisfies executive reporting requirements while protecting your teams.
The goal is to move past passive reporting and build an operational intelligence layer that actively governs execution decisions.
If you want to understand how to measure developer productivity effectively, engineering leaders must shift from tracking individual output to analyzing systemic execution. The right approach combines behavioral telemetry with qualitative insights to understand how work actually flows through the organization.
The pressure to demonstrate engineering performance often leads organizations to pick the easiest data points available. Tracking lines of code or story points completely misses the reality of how software is built¹.
Measuring developer productivity requires focusing on execution signals that actually correlate with business outcomes. You have to evaluate output vs. outcomes to ensure your teams are building the right things efficiently.
A true KPI for a software developer isn't an individual metric but a team-level indicator of speed, quality, and workflow efficiency.
Consulting firms often push for individual contribution metrics to identify low performers. Despite this pressure, stack-ranking developers based on commit counts is a universally detrimental practice that ruins engineering culture².
When you measure individuals, developers chase the metric by taking easy tickets and avoiding complex collaborative work. This creates a system where high velocity actually masks a high accumulation of technical debt.
Focusing on team-level outcomes forces everyone to prioritize the actual delivery of the product.
The rise of AI coding tools has completely broken traditional measurement systems. AI impact isn't just about writing code faster.
These tools artificially inflate raw output and commit counts, but they secretly increase code review wait times. A developer might use AI-generated code to finish a feature in two hours instead of two days.
That massive block of code then sits in a review queue for four days because peers struggle to understand the hidden technical debt and code complexity it introduces. The raw output looks fantastic on a dashboard, so the actual delivery system slows down unnoticed.
Standard industry frameworks provide highly valuable baseline signals for your engineering organization. They give you a structured way to look at developer productivity metrics and establish performance baselines.
Just remember that these frameworks provide signals rather than systemic understanding. They act like a check-engine light for your delivery predictability. You still need operational intelligence to diagnose the actual engine.
The DevOps Research and Assessment team established the industry standard for measuring software delivery performance. These metrics focus strictly on the speed and stability of your Continuous Integration and Continuous Deployment pipelines.
Flow metrics help you understand the friction inside your delivery workflows. They track how work moves from the first commit to the final release.
Cycle time is the most critical metric here because it measures the total time a team spends working on an issue. You must break cycle time down to find the actual workflow bottlenecks.
High cycle times are usually driven by pull request size and excessive review time. When pull requests are too large, wait time increases as reviewers delay the complex task.
Tracking throughput helps you see the volume of work completed, so monitoring review wait times tells you where the system is actually stalling³.
Quantitative metrics only tell half the story. The Satisfaction, Performance, Activity, Communication, Efficiency framework introduces qualitative data to your measurement strategy.
It connects developer satisfaction directly to hard business return on investment. Attitudinal data captures how developers feel about their tooling and processes, while behavioral telemetry tracks what they actually do⁴.
High developer experience scores correlate strongly with low engineering drag and high retention. If your developers are constantly fighting broken environments, their satisfaction drops long before your cycle time increases.
According to benchmark reports from McKinsey and GitHub, teams with high satisfaction scores consistently deliver more reliable code⁵.
Standard frameworks are incredibly useful for setting baselines, but they stop short of solving the actual problem. A common leadership mistake is treating these operational metrics as a complete diagnostic tool rather than just a check-engine light.
When your lead time for changes spikes, the dashboard tells you that a problem exists. It doesn't tell you how to fix it.
This disconnect happens because your execution data lives in disconnected silos. Planning data sits in Jira, code data lives in GitHub, and deployment data resides in your delivery workflows.
This fragmentation creates engineering drag because leaders have to manually piece together what is actually happening. You must move past simply observing metric signals and start building a systemic understanding of how your teams operate.
When a top-level metric shifts, you have to know exactly where to look for the root cause. This requires mapping your quantitative signals directly to the daily habits of your engineering teams.
Connecting these data points enables active decision-making instead of reactive panic.
The fundamental flaw with traditional dashboards is that they measure the output, but an operational intelligence layer measures the systemic context of that output. Dashboards count how many pull requests were merged.
System-level visibility tells you if those pull requests actually moved the business forward or just created future maintenance burdens.
Relying purely on standard telemetry leads to a false sense of security. You might see high commit volumes and assume your teams are highly productive.
Without the context of code complexity and review wait times, you can't see that those commits are actually introducing risk into the system. You have to connect your planning, code, and delivery data to see the true flow of work.
Standard frameworks provide valuable signals, yet they can't explain why performance is changing. This limitation is becoming a critical failure point right now because AI is accelerating raw output and clogging your review pipelines.
Your developers are writing code faster than ever, so that speed is introducing hidden complexity and risk into your delivery systems. Traditional metrics are breaking down under this new reality.
This is exactly why engineering leaders must evolve from passive measurement to an active operational intelligence layer. TargetBoard is an agentic operational intelligence platform designed specifically to solve this systemic gap.
We don't just measure engineering performance. We explain why it's changing. The platform connects planning, code, and delivery data across your existing silos to surface hidden risks before they slow down your teams.
Instead of forcing you to interpret static charts, the platform uses domain-expert AI agents to continuously analyze your research and development execution. These agents monitor your domains for bottlenecks, review churn, and AI-generated code complexity.
This provides the code review intelligence required to flag high-risk pull requests before they merge, giving you true system-level visibility so you can optimize resource allocation and make active decision-making a daily reality. You stop reacting to delayed metric drops and start governing your execution with confidence.
Measuring developer productivity is ultimately about ensuring sustainable development and proving a tangible ROI to your business. You can't achieve this by counting lines of code or stack-ranking your engineers.
You have to measure how effectively your entire system delivers value to the customer.
Keep in mind that implementing systemic measurement takes time and requires a deliberate culture shift. You have to train your managers to look at workflow behaviors instead of individual output.
When you connect your fragmented data and focus on team-level outcomes, you empower your engineering organization to align, prioritize, and ship with absolute predictability.
In the dynamic landscape of technology startups, the reliance on external outsourcing, offshore teams, or agency support is increasingly common. Whether it's for development, product management, QA, IT, support, or marketing, these partnerships can be pivotal. However, aligning the interests of your company with those of your service providers is a nuanced challenge. This article explores the importance of tracking partner performance and how TargetBoard simplifies this crucial task.
Tech startups often turn to external talent for several reasons:
1. Talent Acquisition Challenges: Finding the right talent locally can be tough, prompting companies to look beyond their borders.
2. Cost Reduction: Outsourcing can be a cost-effective solution compared to local hiring.
3. Rapid Scaling: Startups needing to grow quickly often find that external teams provide the necessary bandwidth.
4. Organizational Diversity and Liquidity: Bringing in external teams can introduce fresh perspectives and flexible structures.
Despite the benefits, a significant challenge remains: aligning your company's interests with those of your service providers. Often, these providers are driven by their own goals, primarily maximizing profit, which can sometimes conflict with the needs of their clients.
- A development agency might prioritize quick delivery over quality, leading to technical debt.
- A marketing firm could focus on short-term gains instead of building a sustainable brand strategy.
- IT support services might offer solutions that require constant maintenance, ensuring ongoing dependency and revenue.- An implementation specialist as a premium partner for a major CRM or Cloud might elect to implement a costly or overkill solution.
Keeping tabs on the performance of your partners is not just beneficial; it's essential. It fosters honest conversations, enables better evaluation and planning, and allows for a comparative analysis of various providers. Unfortunately, many companies lack the tools and systems to effectively monitor this performance.
TargetBoard revolutionizes how tech startups can manage and evaluate their external partnerships. With its user-friendly interface and comprehensive metrics, TargetBoard offers a seamless solution for comparing partners, consultants, and agencies against each other and even against your in-house teams.
Effective project management is crucial, especially for tech startups in their growth stage. Despite its importance, many companies overlook this aspect, often entrusting product or development managers with the task without specialized support. This approach, however, overlooks the complexities involved in tracking Key Performance Indicators (KPIs) of a project.
KPIs are essential for measuring the success and efficiency of a project. However, tracking these metrics can be challenging. Data availability, accuracy, and timeliness are common issues. Moreover, companies often recognize the need for KPI tracking after a project has already commenced, leading to retroactive planning and data collection.
A significant consequence of not tracking project KPIs effectively is the lack of visibility into a project's progress. This opacity creates friction among management team members and leads to a considerable waste of time. Managers often find themselves in a constant hustle to compile and present KPIs ad-hoc, multiple times a day. This process not only consumes valuable time but also impedes efficient communication within the team.
In the realm of project management, several KPIs are crucial for monitoring progress and success. These include:
1. Project Completion Rate: Measures the percentage of projects completed within the stipulated timeframe.
2. Budget Variance: Tracks the difference between the budgeted and actual cost of the project.
3. Scope Creep: Monitors any changes or expansions in project scope beyond the original plan.
4. Resource Utilization: Assesses how efficiently resources (both human and material) are used.
5. Milestone Achievement: Tracks the completion of key stages within the project timeline.6. Team Performance: Evaluates the productivity and efficiency of the team members.
Managing multiple projects adds further complexity. Each project may have different KPIs and tracking requirements, making a unified system like TargetBoard essential for coherent and efficient management.
TargetBoard simplifies the process of tracking these KPIs. It integrates seamlessly with existing systems, providing immediate and hassle-free access to essential project metrics. This accessibility is crucial for making informed decisions and keeping projects on track.
TargetBoard is designed to be adaptable. It can be used at any stage of a project, allowing for retroactive data filling and redefining project scopes based on accurate, up-to-date information.Tracking KPIs is a fundamental part of successful project management. TargetBoard offers a streamlined, comprehensive solution, ensuring that project managers have the data they need to guide their projects to successful completion. This tool is indispensable for companies aiming to enhance their project management capabilities and achieve better outcomes.
Startups, in many ways, mirror the journey of living organisms. From inception to maturity, both tread a challenging path, with pitfalls and hazards lurking at every turn. However, by understanding these challenges, startups can better navigate this perilous journey. This article, inspired by the world of biology, seeks to offer a deeper understanding of why startups fail and how they can avoid these pitfalls.
The trials and tribulations of startups are manifold. While numerous studies and articles have outlined various reasons for failure, some stand out more than others:
- Lack of Market Need: Imagine a fish evolving to live on land, only to find out there's no food for it there. Startups, in a similar vein, can develop a product that, while innovative, doesn't cater to any significant market need, leading to its eventual downfall.
- Running Out of Cash: Just as a plant needs water to grow, startups need cash flow to expand and thrive. Without sufficient funds, even the most promising of startups can wilt and die.
- Not the Right Team: Think of this as a beehive where the bees don't cooperate. A disjointed team that lacks the necessary skills or passion can hinder a startup's growth trajectory.
- Competition: In nature, predators can lead to an organism's end. In the business world, competitors, if too dominant or numerous, can outpace and overshadow a budding startup.
1. Miscarriage: Like an embryo that fails to develop, some startups don't make it past the initial stages. They might have a promising idea but fall short in execution. For example, many startups set out with the idea of creating the "next Facebook," but without a unique value proposition or clear strategy, they never move past the conceptual stage.
2. Trauma: Sudden, traumatic events can derail a startup's growth. Imagine a young tree hit by lightning. It's unexpected and can be devastating. A startup might face a sudden exodus of its core team or see a competitor launch a product that's leagues ahead. Blockbuster, for example, was blindsided by the rise of digital streaming services like Netflix, leading to its decline.
3. Chronic Disease: Lingering issues within a startup can be likened to a chronic ailment. A classic case is MoviePass, which offered an unsustainable subscription model. Their high customer acquisition costs, coupled with an unviable business strategy, gradually led to their downfall.
4. Old Age: All organisms have a life cycle, and so do businesses. Kodak, once a giant in the world of photography, struggled to adapt to the digital age, leading to its decline.
5. Toxins: Toxic behaviors and cultural norms can poison a startup from within. Think of it as an organism exposed to harmful substances. For a startup, this can manifest as unethical practices, discriminatory behaviors, or a lack of transparency. The ride-hailing service Uber faced significant backlash due to allegations of a toxic work environment, which had substantial repercussions for the company.
Yet, startups aren't destined for failure. With the right tools and mindset, many of these challenges can be mitigated. TargetBoard stands as a beacon for startups. By ensuring that all departments and team members are on the same page, working towards unified objectives, startups can steer clear of these common pitfalls. In the dynamic world of business, as in nature, the ability to adapt and evolve is paramount.
In conclusion, the interplay of various factors determines the success or failure of a startup. By understanding these factors, and with a touch of foresight and the right tools, startups can not only survive but thrive in the business ecosystem.
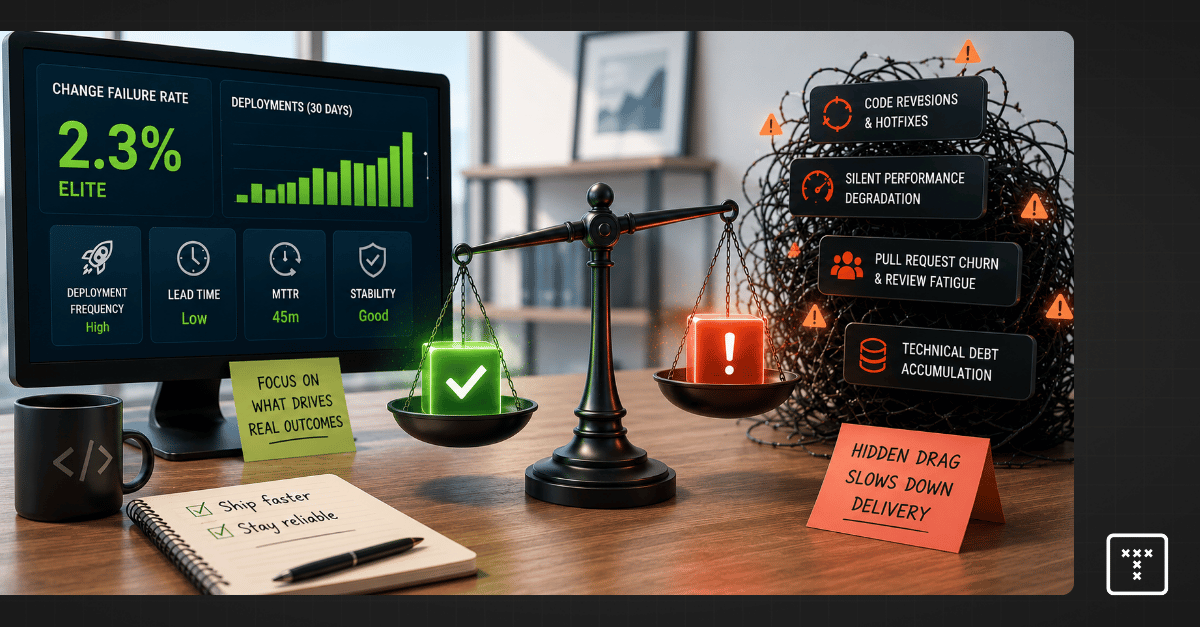
Change failure rate (CFR) measures the percentage of code deployments that result in a failure in production. The goal is to track how often your team pushes code that requires immediate remediation.
This metric serves as a critical counterbalance to deployment frequency. Optimizing strictly for speed often damages quality, so tracking failures ensures your team maintains system stability while shipping features faster. Engineering leaders use this DORA change failure rate signal to balance the inevitable tradeoff between quality versus speed.
Calculating this metric requires standardizing what counts as a deployment and what counts as a failure. You must define these terms consistently across your incident response tools and code repositories.
To calculate change failure rate, use this formula:
(Number of Failed Changes / Total Number of Changes) × 100
Industry benchmarks categorize engineering teams into performance tiers based on their ability to ship code reliably. According to the 2023 Accelerate State of DevOps Report by Google Cloud, you can measure change failure rate against these established standards to gauge your baseline delivery health.
Most engineering leaders limit the definition of failure strictly to hotfixes and rollbacks. This narrow scope misses the broader picture of system degradation.
If a deployment introduces massive technical debt or causes degraded service that doesn't trigger a critical alert, your dashboard will still show a success. This forces leaders to rely on intuition because incomplete data undermines the credibility of engineering reporting. Redefining failure for the modern era means looking at the entire workflow rather than just the final production state to capture the true cost of service patches.
Modern software delivery systems experience friction long before a catastrophic outage occurs. You must expand your definition of failure to capture the hidden costs of code delivery.
A dashboard can easily show an Elite status while your team is actually dealing with high pull request churn. This happens when teams game the metric or pollute the data with inconsistent definitions.
One common mistake is including fix-only deployments in the denominator of your calculation. If you push five hotfixes to resolve a single incident, counting those fixes as new deployments artificially lowers your failure rate. Another pitfall involves poor incident attribution, where third-party cloud outages are counted against internal team performance. These practices create a false sense of stability that operational intelligence must correct to restore trust in your reporting.
Executives must ensure their teams map incidents accurately across the software delivery lifecycle. Messy data makes it impossible to identify root causes and delays critical decision-making.
The rapid adoption of AI coding tools fundamentally changes how we measure delivery risk. These tools drastically increase developer output, so teams write and submit code faster than ever before. Yet this sheer volume of artificial intelligence-generated code contributions introduces unseen complexity into your repositories.
Downstream reviewers simply can't keep up with the flood of new pull requests. This imbalance creates severe review fatigue, where engineers lose the capacity to deeply inspect code for architectural flaws or long-term maintainability issues. The code compiles and passes basic tests, but the underlying structural health of the system degrades quietly.
Unmanaged complexity builds up in your repositories and creates massive workflow friction during the review stage. When a dense, highly complex pull request sits in review for days, engineers eventually rubber-stamp the approval just to clear their queues.
That code merges, sits in the pipeline, and fails days later in production. You then spend valuable engineering cycles on bug prioritization instead of shipping new features. The failure looks like a sudden event on your dashboard, but the root cause was the hidden complexity that bottlenecked your workflow days earlier.
Measuring a failure after it hits production is fundamentally a lagging indicator. Industry frameworks provide useful signals about your software delivery performance, but they don't provide an understanding of why that performance is changing. You need to know where risk enters your system before the code ships to production.
TargetBoard is an agentic operational intelligence platform that helps leadership teams understand how execution is performing, why it's changing, and how to respond. It connects data across company systems, interprets performance through operational intelligence, and uses domain-expert artificial intelligence agents to guide execution decisions.
By surfacing hidden risks like review fatigue, code anomalies, and workflow bottlenecks during the actual code review process, TargetBoard allows you to neutralize the root causes of failure before they merge. This shifts your posture from reactive reporting to proactive delivery confidence, ultimately driving true engineering efficiency.
You can actively prevent production failures by changing how your team handles code before it reaches the main branch. Aligned with the foundational Continuous Delivery principles established by industry experts like Jez Humble and Martin Fowler, shifting quality checks left is critical.
Pushing for speed without guardrails creates severe systemic tradeoffs. You must balance how fast you ship with how well your system actually runs.
Requires connecting cross-system data to accurately predict where failures will occur.
Redefining failure requires you to look beyond standard production deployments and measure the friction happening inside your daily workflows.
Your dashboard is only as valuable as the decisions it enables. Passive metrics show you what broke, so you must adopt active operational intelligence to see why it broke. Understanding these patterns gives you a clear framework to improve engineering efficiency and ensure long-term delivery predictability. Moving away from lagging scorecards allows you to scale your software delivery performance safely and build trust with your board.

Mean time to recovery (MTTR) is the average time it takes your organization to fully restore a system after a failure. This metric serves as one of the most critical lagging indicators of your engineering organization. It reveals how well your systems and teams handle unexpected outages.
A "good" target depends entirely on your operational maturity. The 2023 Accelerate State of DevOps Report indicates that elite performers recover in less than one hour. High performers typically restore service in less than one day. Hitting that elite tier requires more than just fast typing during an incident. It requires clear ownership boundaries and immediate access to system-level data.
You calculate this metric by dividing your total downtime by the number of incidents over a specific period. To calculate recovery speed accurately, track these components:
If a core payment service experiences 120 minutes of total downtime across four separate outages in one month, your recovery speed averages 30 minutes per incident. The clock starts the exact moment the system degrades and stops only when full functionality is confirmed for the end user.
Incident management relies on precise terminology. The four "R" metrics often get conflated, so understanding the boundaries of each helps you pinpoint exactly where bottlenecks occur.
You invest in automated alerting and refine your incident response process, yet your DevOps metrics remain stagnant. The flaw lies in treating slow recovery strictly as a failure of the response team. When metrics plateau, the root cause is rarely a lack of effort. The friction usually stems from upstream bottlenecks that make the system impossible to debug efficiently during a crisis.
Consider a realistic deployment failure where a database schema update breaks a legacy checkout service. Alerts fire from your monitoring tools immediately. Your on-call engineer acknowledges the page in under two minutes, and the team executes the rollback runbook flawlessly. But that database state change can't be reversed without manual intervention from a separate data engineering team.
The issue escalates into a multi-hour outage because cross-team coordination breaks down. The dependencies between the new schema and the legacy service were entirely undocumented. Data silos across Jira, GitHub, and Slack mean the responding engineers can't see who actually owns the upstream database changes. This system variability proves that you can't simply streamline documentation to compensate for fragmented architecture.
Enterprise engineering teams attempt to diagnose these plateaued recovery times using standard industry frameworks. Tracking deployment frequency and change failure rate is standard practice for measuring operational maturity. A common operational mistake is treating these framework metrics as a root cause diagnostic tool rather than a lagging signal.
DevOps Research and Assessment metrics provide signals, but they don't provide understanding. They tell you that a deployment failed or that recovery took four hours. They don't tell you that a massive, highly complex pull request bypassed rigorous code review due to a rushed release management process. Relying solely on these lagging indicators leaves leaders with metrics without context. You see the numbers shift, so you know a problem exists, but you lack the operational intelligence to identify the specific workflow friction causing it.
When an outage strikes, the clock ticks relentlessly while engineers struggle to map the system architecture. Upstream constraints are the actual culprits behind sluggish recovery times. If you want to improve response speed, you must look at how work flows through your continuous delivery pipelines before the code ever reaches production.
A team burdened by high technical debt and review churn will inevitably build brittle systems. These underlying structural issues dictate how quickly your team can isolate a defect.
Modern software delivery relies on a massive web of microservices, and this creates intense workflow friction when things break. Performance data and system context are trapped in data silos. Code lives in GitHub, tickets sit in Jira, and deployment logs are buried in separate observability tools. According to a 2023 Forrester Report on incident response, teams often spend up to 70% of an incident's duration simply trying to locate the root cause and the correct service owner. Fragmented ownership means cross-team boundaries are blurred. If a deployment fails due to an upstream API change, the on-call engineer can't confidently roll back the change without risking further cascading failures.
AI coding assistants are accelerating output, but they also introduce severe hidden complexity into your codebase. A developer might use AI to generate 500 lines of logic that look perfectly clean in a pull request. The reviewer scans the syntax, sees no immediate issues, and approves the merge to keep cycle time low.
In the production environment, that same code triggers complex failures under high load. The defect patterns are entirely unfamiliar because a human did not write the underlying logic. Debugging becomes a nightmare. Responders can't rely on institutional knowledge to trace the error, so they must reverse-engineer the AI-generated logic while the system is down. This hidden code complexity turns a standard five-minute fix into a multi-hour investigation.
Understanding the broader landscape of incident metrics helps you isolate specific reliability risks. Mean time to recovery focuses on restoring service, but it sits alongside other critical measurements that track stability and response initiation.
You can't lower your recovery time simply by paging developers faster or conducting more rigorous post-incident reviews. Fast recovery requires understanding why systems are changing before an incident ever occurs. You must move away from reactive incident management and embrace proactive monitoring anchored in system-level visibility.
TargetBoard is an agentic operational intelligence platform that helps leadership teams understand how execution is performing, why it is changing, and how to respond. It connects data across company systems, interprets performance through operational intelligence, and uses domain-expert AI agents to guide execution decisions.
TargetBoard unifies fragmented data across Jira, GitHub, and your delivery systems into a single trusted model. The platform deploys domain-expert AI agents to map dependencies and detect workflow friction upstream. It identifies AI-generated code risks and surfaces hidden complexity before that code merges into production. This transforms automated alerting from passive dashboards into actionable decisions. We don't just measure engineering performance. We explain why it's changing. This approach gives you the operational intelligence necessary to stabilize your architecture and typically improves true delivery predictability.
Pushing your incident response teams to work faster will only yield diminishing returns. The speed of your recovery is dictated by the clarity of your system architecture and the accuracy of your data.
Improving your mean time to recovery requires a fundamental shift in operational maturity. You must break down data silos, clarify ownership boundaries, and actively manage the hidden complexity introduced by AI coding tools. By gaining true visibility into your engineering efficiency, you can eliminate the upstream friction that causes outages to spiral out of control.

What is velocity vs capacity in Agile? Understanding velocity vs. capacity comes down to separating what a team did in the past from what they can actually do right now. VPs of Engineering often treat velocity versus capacity as interchangeable data points during sprint planning. But they measure entirely different dimensions of engineering operations.
Velocity looks backward at what a team achieved, so it provides a baseline for expectations. Capacity looks forward at who is actually in the room, which grounds those expectations in reality. You can't build a reliable forecast using only one side of this equation.
Velocity is a lagging indicator that measures historical performance. It calculates the average number of completed story points a team delivered over recent sprints. This metric gives you a baseline of past performance under previous conditions. But it doesn't account for new complexities or current workflow friction.
Capacity is a leading indicator that defines future availability. It measures the actual time your team has to work on new commitments based on real-time constraints. This includes tracking team availability after accounting for meetings, operations overhead, and focus hours. Capacity tells you exactly who is in the room and ready to build.
You can't plan a sprint using only one side of the equation. If you only measure velocity, you will overcommit during weeks with high time off and PTO. If you only determine capacity, you lack a benchmark for how much work fits into those available hours. You must combine both to plan sprint cycles effectively.
Follow this sequence to align team commitments with actual execution reality.
Smart resource allocation requires you to commit to less work than your maximum mathematical capacity. This buffer creates a sustainable pace that absorbs complex pull request reviews and inevitable context switching. Operating at 100 percent capacity guarantees that any minor workflow friction will immediately derail your commitments.
Executives often conflate these distinct metrics when evaluating team performance. Understanding the difference between velocity, capacity, and load is critical for diagnosing why a team is burning out.
When team load consistently exceeds actual capacity, delivery predictability collapses. Teams will start cutting corners on code quality or accumulating technical debt just to maintain the illusion of stable velocity.
You have likely sat in a board meeting where engineering leadership reports a perfectly stable velocity, yet the actual product roadmap is slipping by weeks. This scenario sits at the center of the velocity vs capacity debate. The disconnect happens because velocity measures raw output, not true productivity.
A team can easily burn down 40 points of minor bug fixes while the core architectural work stalls completely. When executives treat velocity as a prescriptive performance target rather than a descriptive planning tool, they incentivize measurement theater. Engineers start optimizing for story points to keep the charts looking green, sacrificing sustainable value delivery in the process.
The primary reason teams miss commitments is that engineering operations rely on siloed data. You plan in one system and write code in another, so you never get a clear picture of actuals vs execution data. This fragmentation masks the true workflow friction draining your capacity and directly erodes trust in board-level reporting.
When your measurement systems are disconnected, your capacity planning becomes a guessing game. You see the cycle time increasing, but you can't see the underlying coordination breakdowns causing the delay.
Problem: Engineering managers struggle to reconcile their planning data with actual execution because standard tracking metrics in tools like Jira treat performance as isolated features.
Solution: The Jira velocity chart specifically tracks historical performance by displaying the number of story points completed in past sprints. Jira capacity planning is a separate function that calculates future availability based on user-entered schedules and hours. The critical difference is that both features rely entirely on manual inputs, so neither accounts for the actual code-level bottlenecks or real-time review delays happening in your version control system.
Modern software development has introduced a massive new variable to the capacity equation. Artificial intelligence coding assistants accelerate the initial drafting of code, which artificially inflates your team's velocity. A developer can generate hundreds of lines of logic in minutes.
But this AI code generation impact introduces a hidden drag on your actual capacity. High-complexity pull requests sit in the code review process for days because human reviewers struggle to validate large blocks of AI-generated logic. According to 2023 industry benchmarks from DevEx research, pull requests often sit idle for nearly 70 percent of their lifecycle. This PR review churn drains focus hours and causes multi-day PR delays, even while the team shows a "good" historical velocity on paper.
Your capacity planning must account for the reality of how enterprise engineering actually operates. Unplanned work and urgent incident responses consistently drain focus hours. Context switching between feature development and bug fixing destroys momentum. According to research from the American Psychological Association, shifting between complex tasks can cost up to 40 percent of a professional's productive time.
This friction multiplies when you factor in cross-team dependencies. A team might have the capacity to write the code, but they are blocked waiting on an API from another department. If you ignore these interruptions and the compounding weight of technical debt, your capacity plan is just a theoretical best-case scenario. This becomes especially critical during holiday weeks or major operational incidents, where actual capacity drops to a fraction of your standard baseline.
Standard measurement frameworks like DORA and SPACE provide valuable industry benchmarks. But they are only partial signals. They don't tell you that cycle time increased because three high-complexity, AI-generated PRs sat in review for four days due to a cross-team coordination breakdown.
The primary gap in delivery predictability is not a lack of metrics. The gap is a lack of operational intelligence connecting those metrics to actual execution. You need a unified data layer to see what is actually happening across Jira and GitHub so you can understand why execution stalls.
TargetBoard is an agentic operational intelligence platform that connects data across company systems, interprets performance through operational intelligence, and uses domain-expert AI agents to guide execution decisions. It bridges the gap between static planning metrics and actual delivery. TargetBoard’s domain-expert AI agents surface hidden workflow bottlenecks in real time. It acts as a systemic execution layer that explains why performance is changing, empowering leaders to make proactive decisions with absolute delivery confidence and align their engineering efforts with actual business outcomes.
Shifting your focus from outcome vs output requires a fundamental change in how you view engineering data. Agile velocity vs capacity is not just a math problem for your scrum masters to solve. It's a strategic framework for understanding your delivery predictability.
Understanding these patterns gives you a clear operational model for your next sprint planning session. Stop relying on lagging indicators to guess your future availability. Connect your planning data to your execution reality, identify the hidden friction draining your focus hours, and build a system that actually explains your engineering performance.

.webp)



