



Employee performance management in modern engineering is the continuous process of aligning software delivery systems to business goals by identifying and removing workflow bottlenecks. It shifts the leadership focus away from isolated developer output and toward systemic execution alignment.
The traditional performance management process relies on individual appraisals, subjective feedback, and isolated activity metrics like lines of code. This outdated approach assumes that maximizing individual effort will automatically result in faster delivery.
The modern engineering approach recognizes that software development is a highly collaborative system. An individual developer might produce code rapidly, but that code can sit in a review queue for days due to complex architecture or cross-team dependencies. Modern performance management measures these systemic workflows to explain why delivery slows down and how leaders can restore predictability.
The standard human resources performance management cycle involves five distinct phases: planning, monitoring, developing, rating, and rewarding. Traditional corporate departments use this continuous feedback loop to evaluate staff and conduct traditional performance reviews.
This framework completely breaks down in agile software development. Tracking individual output ignores the reality of cross-team coordination and hidden technical debt. Software delivery is a complex system, so you can't fix a systemic bottleneck by rating a single developer's isolated metrics.
Modern engineering organizations replace this outdated cycle with an execution alignment model. This updated approach focuses on objective data signals and operational intelligence to drive better delivery decisions.
You know the frustration of unpredictable delivery. You sit in leadership meetings drowning in data silos across Jira and GitHub, yet you still can't explain exactly why velocity is dropping. The immediate instinct is to buy employee monitoring software to see what developers are doing all day. That approach destroys morale and completely misses the mark.
Visibility is no longer the problem, so you need to focus on true understanding. To manage performance effectively, you must stop asking who is working and start identifying where the work is actually stuck. TargetBoard is an agentic operational intelligence platform that helps leadership teams understand how execution is performing, why it's changing, and how to respond.
It acts as the connective tissue that translates fragmented decision-making signals into clear execution priorities without relying on toxic employee surveillance.
CEOs and board members often ask about the top employee performance metrics to track, but tracking individual KPIs like lines of code creates a toxic culture and incentivizes the wrong behaviors. Research indicates that strict individual productivity monitoring actively degrades team morale and reduces overall output by creating environments of low trust.
Studies on agile environments confirm that evaluating a complex system by isolating a single contributor consistently fails to improve delivery speeds². Instead, you need to track systemic workflow key performance indicators that actually impact delivery predictability.
Artificial intelligence is fundamentally changing how work is produced. I recently worked with an engineering organization that rolled out AI coding assistants across their teams. Within a month, their raw code output spiked dramatically. The leadership team initially celebrated this increase in volume, yet their actual delivery timelines quickly ground to a halt.
The problem was a massive bottleneck in the code review phase. The teams were generating code faster than human reviewers could safely validate it. This created a surge in pull request complexity and introduced hidden technical debt into the codebase.
You can't solve this artificial intelligence impact by telling reviewers to work faster. You have to use a systemic performance approach to manage this new complexity gap, ensuring that increased output does not destroy downstream predictability.
Standard measurement frameworks like DORA and SPACE are highly popular in modern engineering. These frameworks provide useful signals about software delivery performance, but they do not provide true operational understanding. A dashboard might show you that your lead time is increasing, yet it will not tell you why that delay is happening or how to fix it.
Metrics without context actively erode engineering team trust. When leaders see numbers shift but can't explain the cause, they make poor decisions based on assumptions.
To find the actual root cause analysis, you must map workflow friction across your systems visually. You might discover that a drop in velocity is not a developer productivity issue, but a cross-team coordination breakdown blocking a critical path.
Engineering leaders face intense pressure to justify their budgets to the board. When you rely on outdated performance appraisals and individual tracking, you can't confidently explain how engineering effort translates into business value. You end up with a frustrated team and skeptical executives.
Transitioning away from individual surveillance and toward systemic execution alignment is the only sustainable way to build operational trust. This shift provides the objective data signals and real-time operational visibility required to empower your teams. When you focus on removing blockers and optimizing workflows, you restore delivery predictability and clearly demonstrate your engineering return on investment.
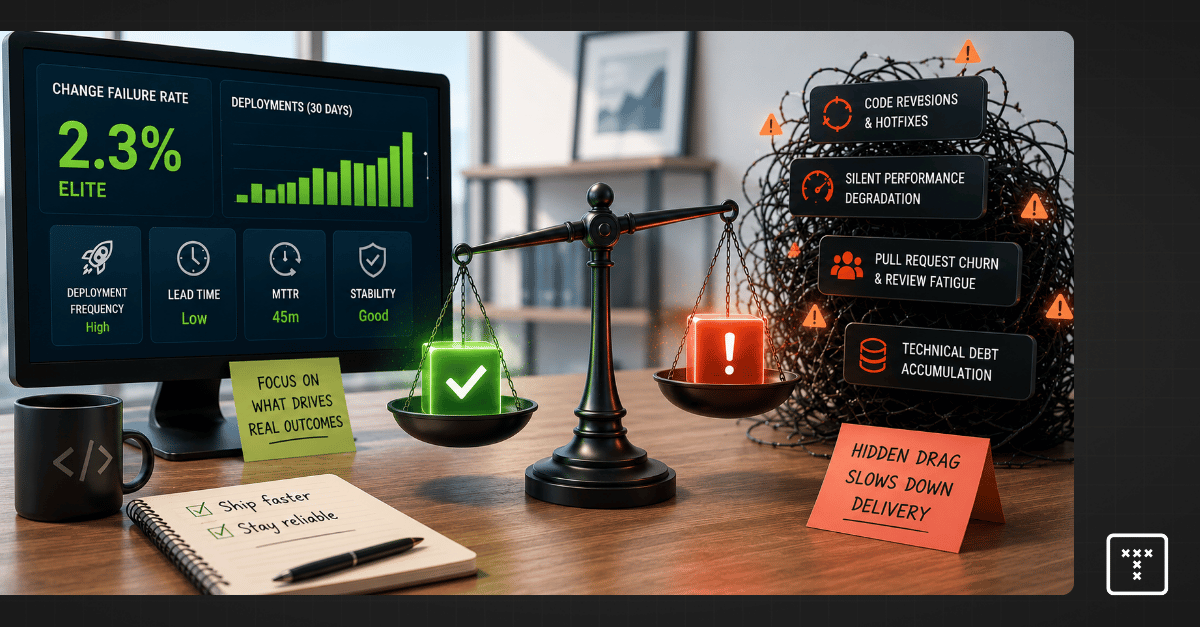
Change failure rate (CFR) measures the percentage of code deployments that result in a failure in production. The goal is to track how often your team pushes code that requires immediate remediation.
This metric serves as a critical counterbalance to deployment frequency. Optimizing strictly for speed often damages quality, so tracking failures ensures your team maintains system stability while shipping features faster. Engineering leaders use this DORA change failure rate signal to balance the inevitable tradeoff between quality versus speed.
Calculating this metric requires standardizing what counts as a deployment and what counts as a failure. You must define these terms consistently across your incident response tools and code repositories.
To calculate change failure rate, use this formula:
(Number of Failed Changes / Total Number of Changes) × 100
Industry benchmarks categorize engineering teams into performance tiers based on their ability to ship code reliably. According to the 2023 Accelerate State of DevOps Report by Google Cloud, you can measure change failure rate against these established standards to gauge your baseline delivery health.
Most engineering leaders limit the definition of failure strictly to hotfixes and rollbacks. This narrow scope misses the broader picture of system degradation.
If a deployment introduces massive technical debt or causes degraded service that doesn't trigger a critical alert, your dashboard will still show a success. This forces leaders to rely on intuition because incomplete data undermines the credibility of engineering reporting. Redefining failure for the modern era means looking at the entire workflow rather than just the final production state to capture the true cost of service patches.
Modern software delivery systems experience friction long before a catastrophic outage occurs. You must expand your definition of failure to capture the hidden costs of code delivery.
A dashboard can easily show an Elite status while your team is actually dealing with high pull request churn. This happens when teams game the metric or pollute the data with inconsistent definitions.
One common mistake is including fix-only deployments in the denominator of your calculation. If you push five hotfixes to resolve a single incident, counting those fixes as new deployments artificially lowers your failure rate. Another pitfall involves poor incident attribution, where third-party cloud outages are counted against internal team performance. These practices create a false sense of stability that operational intelligence must correct to restore trust in your reporting.
Executives must ensure their teams map incidents accurately across the software delivery lifecycle. Messy data makes it impossible to identify root causes and delays critical decision-making.
The rapid adoption of AI coding tools fundamentally changes how we measure delivery risk. These tools drastically increase developer output, so teams write and submit code faster than ever before. Yet this sheer volume of artificial intelligence-generated code contributions introduces unseen complexity into your repositories.
Downstream reviewers simply can't keep up with the flood of new pull requests. This imbalance creates severe review fatigue, where engineers lose the capacity to deeply inspect code for architectural flaws or long-term maintainability issues. The code compiles and passes basic tests, but the underlying structural health of the system degrades quietly.
Unmanaged complexity builds up in your repositories and creates massive workflow friction during the review stage. When a dense, highly complex pull request sits in review for days, engineers eventually rubber-stamp the approval just to clear their queues.
That code merges, sits in the pipeline, and fails days later in production. You then spend valuable engineering cycles on bug prioritization instead of shipping new features. The failure looks like a sudden event on your dashboard, but the root cause was the hidden complexity that bottlenecked your workflow days earlier.
Measuring a failure after it hits production is fundamentally a lagging indicator. Industry frameworks provide useful signals about your software delivery performance, but they don't provide an understanding of why that performance is changing. You need to know where risk enters your system before the code ships to production.
TargetBoard is an agentic operational intelligence platform that helps leadership teams understand how execution is performing, why it's changing, and how to respond. It connects data across company systems, interprets performance through operational intelligence, and uses domain-expert artificial intelligence agents to guide execution decisions.
By surfacing hidden risks like review fatigue, code anomalies, and workflow bottlenecks during the actual code review process, TargetBoard allows you to neutralize the root causes of failure before they merge. This shifts your posture from reactive reporting to proactive delivery confidence, ultimately driving true engineering efficiency.
You can actively prevent production failures by changing how your team handles code before it reaches the main branch. Aligned with the foundational Continuous Delivery principles established by industry experts like Jez Humble and Martin Fowler, shifting quality checks left is critical.
Pushing for speed without guardrails creates severe systemic tradeoffs. You must balance how fast you ship with how well your system actually runs.
Requires connecting cross-system data to accurately predict where failures will occur.
Redefining failure requires you to look beyond standard production deployments and measure the friction happening inside your daily workflows.
Your dashboard is only as valuable as the decisions it enables. Passive metrics show you what broke, so you must adopt active operational intelligence to see why it broke. Understanding these patterns gives you a clear framework to improve engineering efficiency and ensure long-term delivery predictability. Moving away from lagging scorecards allows you to scale your software delivery performance safely and build trust with your board.

Mean time to recovery (MTTR) is the average time it takes your organization to fully restore a system after a failure. This metric serves as one of the most critical lagging indicators of your engineering organization. It reveals how well your systems and teams handle unexpected outages.
A "good" target depends entirely on your operational maturity. The 2023 Accelerate State of DevOps Report indicates that elite performers recover in less than one hour. High performers typically restore service in less than one day. Hitting that elite tier requires more than just fast typing during an incident. It requires clear ownership boundaries and immediate access to system-level data.
You calculate this metric by dividing your total downtime by the number of incidents over a specific period. To calculate recovery speed accurately, track these components:
If a core payment service experiences 120 minutes of total downtime across four separate outages in one month, your recovery speed averages 30 minutes per incident. The clock starts the exact moment the system degrades and stops only when full functionality is confirmed for the end user.
Incident management relies on precise terminology. The four "R" metrics often get conflated, so understanding the boundaries of each helps you pinpoint exactly where bottlenecks occur.
You invest in automated alerting and refine your incident response process, yet your DevOps metrics remain stagnant. The flaw lies in treating slow recovery strictly as a failure of the response team. When metrics plateau, the root cause is rarely a lack of effort. The friction usually stems from upstream bottlenecks that make the system impossible to debug efficiently during a crisis.
Consider a realistic deployment failure where a database schema update breaks a legacy checkout service. Alerts fire from your monitoring tools immediately. Your on-call engineer acknowledges the page in under two minutes, and the team executes the rollback runbook flawlessly. But that database state change can't be reversed without manual intervention from a separate data engineering team.
The issue escalates into a multi-hour outage because cross-team coordination breaks down. The dependencies between the new schema and the legacy service were entirely undocumented. Data silos across Jira, GitHub, and Slack mean the responding engineers can't see who actually owns the upstream database changes. This system variability proves that you can't simply streamline documentation to compensate for fragmented architecture.
Enterprise engineering teams attempt to diagnose these plateaued recovery times using standard industry frameworks. Tracking deployment frequency and change failure rate is standard practice for measuring operational maturity. A common operational mistake is treating these framework metrics as a root cause diagnostic tool rather than a lagging signal.
DevOps Research and Assessment metrics provide signals, but they don't provide understanding. They tell you that a deployment failed or that recovery took four hours. They don't tell you that a massive, highly complex pull request bypassed rigorous code review due to a rushed release management process. Relying solely on these lagging indicators leaves leaders with metrics without context. You see the numbers shift, so you know a problem exists, but you lack the operational intelligence to identify the specific workflow friction causing it.
When an outage strikes, the clock ticks relentlessly while engineers struggle to map the system architecture. Upstream constraints are the actual culprits behind sluggish recovery times. If you want to improve response speed, you must look at how work flows through your continuous delivery pipelines before the code ever reaches production.
A team burdened by high technical debt and review churn will inevitably build brittle systems. These underlying structural issues dictate how quickly your team can isolate a defect.
Modern software delivery relies on a massive web of microservices, and this creates intense workflow friction when things break. Performance data and system context are trapped in data silos. Code lives in GitHub, tickets sit in Jira, and deployment logs are buried in separate observability tools. According to a 2023 Forrester Report on incident response, teams often spend up to 70% of an incident's duration simply trying to locate the root cause and the correct service owner. Fragmented ownership means cross-team boundaries are blurred. If a deployment fails due to an upstream API change, the on-call engineer can't confidently roll back the change without risking further cascading failures.
AI coding assistants are accelerating output, but they also introduce severe hidden complexity into your codebase. A developer might use AI to generate 500 lines of logic that look perfectly clean in a pull request. The reviewer scans the syntax, sees no immediate issues, and approves the merge to keep cycle time low.
In the production environment, that same code triggers complex failures under high load. The defect patterns are entirely unfamiliar because a human did not write the underlying logic. Debugging becomes a nightmare. Responders can't rely on institutional knowledge to trace the error, so they must reverse-engineer the AI-generated logic while the system is down. This hidden code complexity turns a standard five-minute fix into a multi-hour investigation.
Understanding the broader landscape of incident metrics helps you isolate specific reliability risks. Mean time to recovery focuses on restoring service, but it sits alongside other critical measurements that track stability and response initiation.
You can't lower your recovery time simply by paging developers faster or conducting more rigorous post-incident reviews. Fast recovery requires understanding why systems are changing before an incident ever occurs. You must move away from reactive incident management and embrace proactive monitoring anchored in system-level visibility.
TargetBoard is an agentic operational intelligence platform that helps leadership teams understand how execution is performing, why it is changing, and how to respond. It connects data across company systems, interprets performance through operational intelligence, and uses domain-expert AI agents to guide execution decisions.
TargetBoard unifies fragmented data across Jira, GitHub, and your delivery systems into a single trusted model. The platform deploys domain-expert AI agents to map dependencies and detect workflow friction upstream. It identifies AI-generated code risks and surfaces hidden complexity before that code merges into production. This transforms automated alerting from passive dashboards into actionable decisions. We don't just measure engineering performance. We explain why it's changing. This approach gives you the operational intelligence necessary to stabilize your architecture and typically improves true delivery predictability.
Pushing your incident response teams to work faster will only yield diminishing returns. The speed of your recovery is dictated by the clarity of your system architecture and the accuracy of your data.
Improving your mean time to recovery requires a fundamental shift in operational maturity. You must break down data silos, clarify ownership boundaries, and actively manage the hidden complexity introduced by AI coding tools. By gaining true visibility into your engineering efficiency, you can eliminate the upstream friction that causes outages to spiral out of control.

.webp)



